El ecosistema de los Large Language Models (LLMs) no da tregua. Cada semana, las innovaciones se suceden a un ritmo vertiginoso, y mantenerse al día no es solo una cuestión de curiosidad, sino una necesidad estratégica para cualquier desarrollador, arquitecto o CTO que opere en el frente de la IA generativa. En este contexto, el reciente lanzamiento de xAI Grok 4.1 no es un mero «incremental improvement», sino una declaración de intenciones que posiciona a Grok como un contendiente de peso en la carrera por la supremacía de los LLMs en entornos de producción.
Desde la trinchera de proyectos reales, donde cada mejora en fiabilidad, rendimiento o capacidad creativa se traduce directamente en ROI y en la viabilidad de una solución, el análisis de modelos como Grok 4.1 es crucial. No se trata solo de las métricas de laboratorio, sino de cómo estas se materializan en arquitecturas robustas y casos de uso de negocio. En este artículo, desglosaremos las implicaciones técnicas de Grok 4.1, su posicionamiento estratégico y lo que significa para la toma de decisiones en el diseño e implementación de soluciones GenAI.
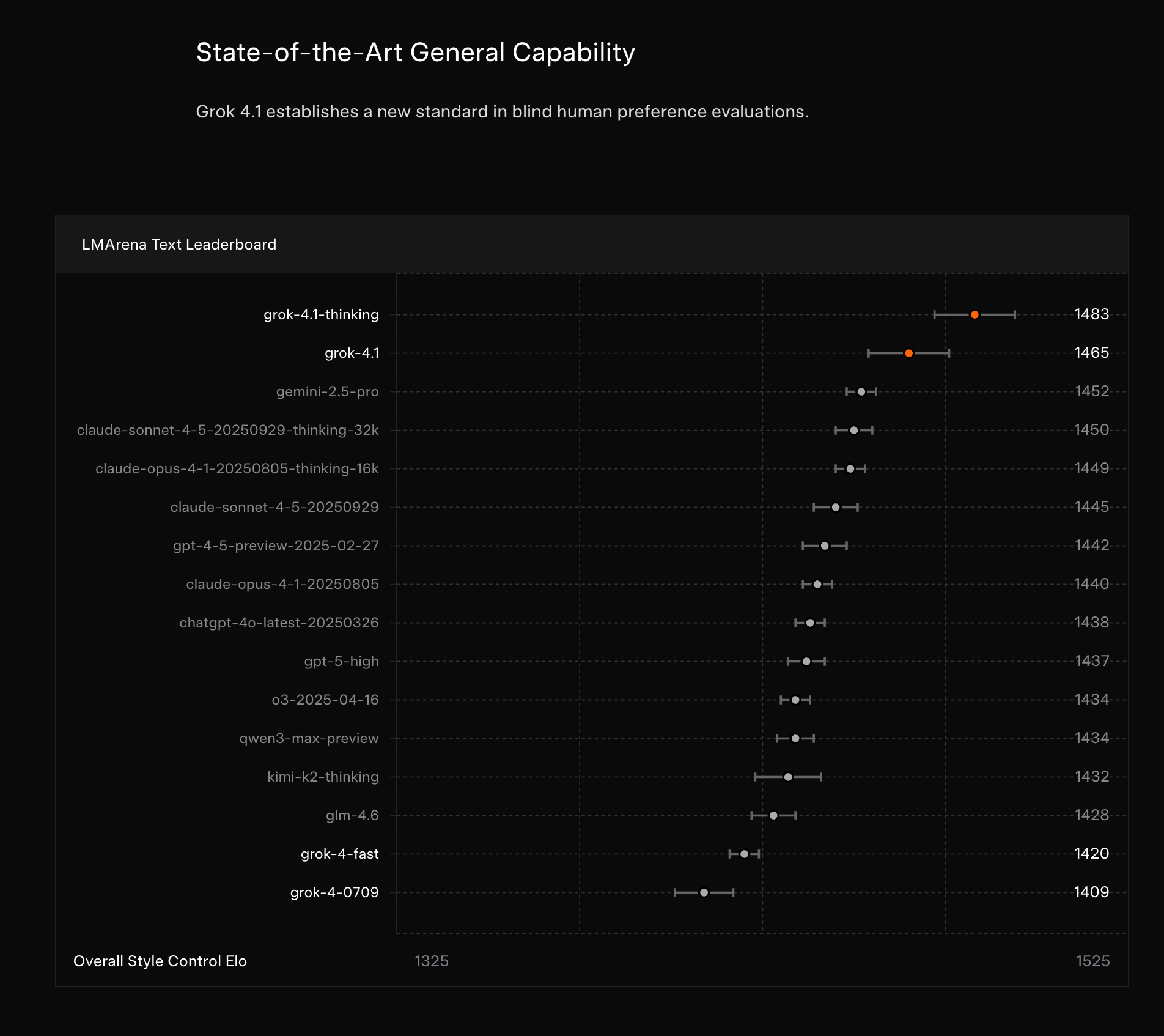
El Salto de Rendimiento: Entendiendo los Benchmarks de Grok 4.1
La primera carta de presentación de Grok 4.1 es su impresionante desempeño en benchmarks clave. El modelo ha escalado a la posición #1 en el Text LMArena con un Elo de 1483, superando a competidores establecidos. Además, ha logrado las mejores puntuaciones en EQBench, un indicador de su superioridad en tareas de comprensión y generación de texto. Pero, ¿qué significan realmente estas cifras para un ingeniero que está evaluando qué LLM integrar en su stack?
LMArena Elo y EQBench: Más Allá de la Cifra Bruta
Para un arquitecto, un Elo de 1483 en LMArena no es solo un número; es una señal de que el modelo ha sido consistentemente preferido por evaluadores humanos en una amplia gama de prompts. Este tipo de benchmark, basado en comparaciones por pares y feedback humano, es particularmente valioso porque refleja la «usabilidad» y la calidad percibida en escenarios diversos, algo que los benchmarks sintéticos a menudo no capturan. Un modelo con un Elo alto tiende a generar respuestas más coherentes, relevantes y bien estructuradas, lo que reduce la necesidad de post-procesamiento o de complejos sistemas de guardrails en producción.
Por otro lado, EQBench evalúa la capacidad del modelo para responder preguntas con precisión y relevancia. Para aplicaciones empresariales donde la veracidad y la contextualización son críticas (pensemos en chatbots de soporte técnico, sistemas de análisis legal o asistentes médicos), un alto rendimiento en EQBench significa que Grok 4.1 tiene una base sólida para ofrecer respuestas fiables. En mi experiencia, estas métricas son un buen punto de partida, pero siempre recomiendo complementarlas con pruebas internas adaptadas a los dominios específicos y los patrones de prompt que se usarán en producción. Un baseline robusto de evaluación es fundamental en cualquier pipeline de LLMOps.
La Fiabilidad en Producción: La Batalla Crucial contra las Alucinaciones
Quizás la mejora más significativa y de mayor impacto para el despliegue en producción es la reducción sustancial en las alucinaciones de Grok 4.1. Para los que hemos desplegado LLMs en entornos empresariales, sabemos que las alucinaciones son el talón de Aquiles de la IA generativa. Un modelo que «inventa» hechos o elabora respuestas plausibles pero incorrectas puede socavar la confianza del usuario, generar errores críticos en la toma de decisiones y, en última instancia, destruir el ROI de un proyecto.
Impacto Directo en Arquitecturas RAG y Agentes
Una mejora en la capacidad anti-alucinación de un LLM base tiene un efecto cascada en toda la arquitectura. Consideremos un sistema RAG (Retrieval-Augmented Generation) típico, construido con FastAPI, LangChain y una base de vectores como ChromaDB o Pinecone. En estos sistemas, la precisión del retriever es fundamental, pero la capacidad del LLM para sintetizar la información recuperada sin introducir falsedades es igualmente crítica.
Con un modelo como Grok 4.1, que alucina menos, podemos:
- Simplificar el Prompt Engineering: Reducir la complejidad de los prompts diseñados para mitigar alucinaciones, permitiendo prompts más directos y enfocados en la tarea.
- Mejorar la Fiabilidad de las Respuestas: Las respuestas generadas serán inherentemente más dignas de confianza, lo que es vital en sectores regulados o en aplicaciones de misión crítica.
- Optimizar los Guardrails y la Post-validación: Aunque los guardrails seguirán siendo necesarios para la robustez, la carga sobre ellos se aligera, permitiendo un diseño más eficiente y menos propenso a errores.
- Desarrollar Agentes más Estables: Los agentes de IA, que encadenan múltiples llamadas al LLM para realizar tareas complejas (utilizando patrones como ReAct con LangGraph), se benefician enormemente de modelos menos propensos a alucinar, ya que cada paso en la cadena de razonamiento es más fiable.
Esta capacidad anti-alucinación es un diferenciador clave que no solo mejora la calidad del output, sino que también reduce la complejidad de desarrollo y los costos de mantenimiento de los sistemas GenAI en producción. Es una inversión directa en la estabilidad y la confianza del usuario final.
Además de la fiabilidad, Grok 4.1 destaca por sus mejoras significativas en la escritura creativa y un control de estilo más sofisticado. Si bien la precisión es fundamental, la capacidad de generar contenido con un tono, estilo y creatividad específicos abre un abanico de casos de uso que van más allá de las respuestas factuales.
Aplicaciones de Negocio para la Creatividad Controlada
Para un CTO o un arquitecto, estas mejoras no son solo académicas. Tienen implicaciones directas en áreas como:
* Generación de Contenido de Marketing: Creación automatizada de textos para redes sociales, descripciones de productos, emails promocionales, adaptando el tono a diferentes audiencias o campañas.
* Personalización de Experiencias de Usuario: Generación de respuestas de chatbots o interfaces conversacionales que se ajusten al estilo de interacción preferido por el usuario, o que mantengan la voz de marca de la empresa.
* Asistencia en Redacción Técnica y Documentación: Generar borradores de documentación, especificaciones técnicas o incluso código con comentarios que sigan un estilo o convención específica de la empresa.
* Creación de Narrativas y Guiones: En sectores como el entretenimiento o la educación, donde la generación de historias o diálogos atractivos es clave.
El «control de estilo» implica que, mediante un prompt engineering avanzado, podemos guiar al modelo para que genere un output que no solo sea correcto, sino que también «suene» como queremos. Esto requiere una comprensión profunda de cómo estructurar los prompts, utilizando few-shot examples, system instructions claras y constraints para moldear la salida del LLM. Es una habilidad que, en la era de los LLMs, se vuelve tan crítica como la optimización de algoritmos o la gestión de bases de datos.
El Ajedrez de los LLMs: Grok 4.1 en el Ecosistema Competitivo
El lanzamiento de Grok 4.1 se produce en un momento de intensa competencia, justo antes del esperado lanzamiento de Gemini 3. Esta dinámica subraya la «carrera armamentística» en el desarrollo de LLMs, donde cada actor busca consolidar su posición.
Posicionamiento Estratégico y Comparativas
- Frente a Grok 4: Grok 4.1 representa una mejora del 65% en pruebas A/B respecto a su predecesor, lo que indica una curva de aprendizaje y optimización agresiva por parte de xAI.
- Frente a Gemini: El análisis sugiere que Grok 4.1 se posiciona como una opción «más robusta» que Gemini 2.5, aunque «presumiblemente más débil» que el anticipado Gemini 3. Esta es una comparativa clave para quienes están evaluando el ecosistema de Google.
- Frente a GPT 5.1: Las mejoras en escritura creativa de Grok 4.1 compiten directamente con las expectativas y rumores de mejoras similares en GPT 5.1.
Para CTOs y arquitectos, esta competencia es una espada de doble filo. Por un lado, impulsa una innovación sin precedentes, ofreciendo modelos cada vez más potentes y versátiles. Por otro, introduce una complejidad considerable en la toma de decisiones:
- Volatilidad del Ecosistema: Los modelos de hoy pueden ser superados mañana. La elección de un LLM no es estática, y las arquitecturas deben ser lo suficientemente flexibles para permitir cambios de modelo con una fricción mínima. Esto implica interfaces bien definidas y abstracciones (como las que ofrece LangChain o LlamaIndex).
- Evaluación Continua: La necesidad de un pipeline de MLOps robusto para la evaluación y el monitoreo de LLMs se vuelve más crítica que nunca. No basta con seleccionar un modelo; hay que validarlo continuamente frente a las métricas de negocio y el rendimiento en producción.
- Consideraciones de Costo y Latencia: Más allá del rendimiento cualitativo, las decisiones se basan en el costo por token, la latencia de las API y la disponibilidad de recursos computacionales. Un modelo con un rendimiento ligeramente inferior pero significativamente más económico o rápido puede ser la opción preferente para ciertos casos de uso masivos.
Implicaciones Prácticas para el Ingeniero y el Arquitecto de GenAI
Las innovaciones de Grok 4.1 y la dinámica del mercado global de LLMs tienen un impacto directo en cómo diseñamos, construimos y mantenemos sistemas de IA generativa.
1. Modelos como Componentes Desacoplados
La volatilidad del panorama de LLMs refuerza la necesidad de tratar a los modelos como componentes desacoplados dentro de nuestra arquitectura. Utilizar frameworks de orquestación como LangChain o LlamaIndex permite intercambiar modelos (OpenAI, Gemini, Grok, modelos open-source) con cambios mínimos en el código de la aplicación. Esto es fundamental para la agilidad y la capacidad de adaptación.
Esta abstracción no solo facilita el cambio de modelos, sino que también permite la experimentación y las pruebas A/B con diferentes LLMs para encontrar el equilibrio óptimo entre rendimiento, costo y calidad para un caso de uso específico.
2. Fortalecimiento de Arquitecturas RAG
La reducción de alucinaciones en Grok 4.1 es una bendición para las arquitecturas RAG. En un microservicio de RAG construido con FastAPI, donde se orquesta la recuperación de documentos de una base de vectores y su posterior síntesis por el LLM, un modelo más fiable significa:
* Menos Pos-procesamiento: La necesidad de complejas etapas de validación o corrección de la salida del LLM se minimiza.
* Confianza en la Fuente: Si el retriever ha hecho bien su trabajo, un LLM como Grok 4.1 tiene más probabilidades de ceñirse a la información proporcionada sin «inventar».
* Mejora en la Calidad del Contexto: Permite centrar los esfuerzos de ingeniería en optimizar la calidad de los embeddings, la estrategia de recuperación y el pre-procesamiento de los documentos, sabiendo que el LLM base es robusto.
3. MLOps para LLMs: Evaluación y Monitoreo Continuo
La rapidez con la que emergen nuevos modelos y sus mejoras recalca la importancia de un robusto pipeline de LLMOps. Esto incluye:
* Evaluación Automática: Implementar métricas y test sets que evalúen la calidad de las respuestas (precisión, coherencia, reducción de alucinaciones) de forma programática. Herramientas como Gen AI Evaluation Service o frameworks de evaluación personalizados son esenciales.
* Monitoreo en Producción: Vigilar métricas clave como la latencia, el costo por token, la tasa de errores y, lo más importante, la calidad de las respuestas en tiempo real (por ejemplo, mediante feedback de usuario o comparaciones con golden answers).
* Versión de Modelos y Prompts: Tratar los modelos y los **prompts` como código, versionándolos y aplicando prácticas de CI/CD para una gestión controlada de los cambios.
Navegando la Ola de la Innovación en GenAI
El lanzamiento de xAI Grok 4.1 es un recordatorio contundente de la velocidad y la profundidad de la innovación en el campo de la IA generativa. Para desarrolladores, arquitectos y CTOs, no se trata solo de observar las noticias, sino de analizar críticamente las implicaciones técnicas y de negocio de cada nuevo modelo.
Grok 4.1 se establece como un competidor formidable, destacando en rendimiento, fiabilidad (especialmente en la mitigación de alucinaciones) y capacidades creativas. Estas mejoras tienen un impacto directo en la construcción de sistemas GenAI más robustos, eficientes y valiosos para el negocio. La clave, como siempre, reside en la aplicación práctica de este conocimiento: evaluar modelos en el contexto de proyectos reales, diseñar arquitecturas flexibles y resilientes, y mantener un enfoque riguroso en MLOps para asegurar que la promesa de la IA generativa se traduzca en resultados medibles y sostenibles.
En GHEN Digital, nuestra filosofía es clara: el conocimiento técnico debe ser práctico, basado en la experiencia y orientado a resolver problemas reales. Grok 4.1 es un paso más en esta evolución, y comprender sus capacidades es fundamental para diseñar la próxima generación de soluciones de IA.
📚 Referencias y Fuentes
Este artículo se ha elaborado consultando las siguientes fuentes: news.smol.ai