Cómo construimos un sistema resiliente de generación de imágenes con Vertex AI para 8 totems interactivos en el stand de la Comunidad Valenciana para la multitudinaria feria FITUR que tuvo lugar en Madrid del 21 al 25 de Enero.
El Proyecto
FotoIA nació como el corazón tecnológico del stand de la Comunidad Valenciana en FITUR 2026, la feria internacional de turismo más importante de España. La idea era simple pero ambiciosa: permitir que los visitantes se fotografiaran y, en segundos, aparecer integrados fotorrealistamente en los destinos más icónicos de Valencia.

La Visión
Imagina tomarte una foto en un totem interactivo y, 30 segundos después, verte a ti mismo contemplando el atardecer desde los acantilados de Benidorm, paseando por el casco histórico de Morella, disfrutando de las playas de la Costa Blanca o celebrando las Fallas en Valencia.
No era un simple «recortar y pegar». La IA debía entender la escena, adaptar la iluminación, la perspectiva, incluso la ropa del usuario para que encajara naturalmente en cada contexto. Al principio probamos con modelos de recorte que tomamos de HuggingFace como
- Robust Video Matting (RVM) (PyTorch): muy preciso y ligero.
- MODNet: enfocado en retratos humanos, rápido y eficaz.
- U^2-Net: modelo muy usado para background removal.
Pero luego necesitabamos un efecto WOW! y en este momento ese efecto solo podia ser logrado por los modelos Nano Banana de Google.
La primera arquitectura entonces fue:
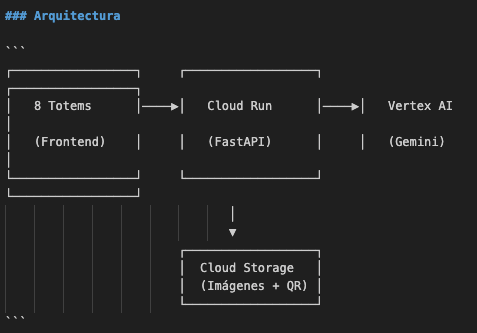
Stack tecnológico:
- Backend: FastAPI sobre Cloud Run (auto-scaling 2-10 instancias)
- IA: Vertex AI con Gemini 3 Pro Image Preview + Gemini 2.5 Flash como fallback
- Storage: Google Cloud Storage para assets y resultados
- Deploy: Cloud Build con CI/CD automático desde GitHub
Los Desafíos
1. El Problema de los 8 Totems Simultáneos
El primer desafío apareció antes de empezar: 8 totems funcionando en paralelo significaban 8 requests potencialmente simultáneos a la API de Vertex AI. Con visitantes haciendo cola en cada totem, los picos de demanda eran inevitables.
El problema del «Thundering Herd»: Cuando un totem fallaba por timeout, el usuario reintentaba. Si esto pasaba en varios totems a la vez, todos reintentaban simultáneamente, amplificando el problema.
Solución implementada: Jitter aleatorio antes de cada request.
# Desincronizar requests de los 8 totems
initial_jitter = random.uniform(0.1, 1.2)
await asyncio.sleep(initial_jitter)Este pequeño delay aleatorio de 0.1 a 1.2 segundos distribuía las requests en el tiempo, evitando que golpearan la API todas al mismo instante.
2. La Latencia de Gemini Pro
Gemini 3 Pro Image Preview produce resultados espectaculares, pero tiene un costo: latencia variable. En condiciones normales respondía en 20-40 segundos, pero bajo carga podía superar los 2 minutos.
El dilema: ¿Esperamos la mejor calidad o priorizamos la velocidad?
Solución: Timeout agresivo con fallback a modelo más rápido.
# Intentar con Pro, pero no esperar más de 40s
try:
image_bytes = await asyncio.wait_for(
generate_with_pro(),
timeout=40.0
)
except asyncio.TimeoutError:
# Fallback a Flash (más rápido, ligeramente menor calidad)
image_bytes = await generate_with_flash()La clave fue encontrar el balance: 40 segundos era suficiente para que Pro completara en el 70% de los casos, pero no tanto como para frustrar al usuario si fallaba.
3. El Error 429: Resource Exhausted
El día del evento, empezamos a ver un patrón preocupante en los logs:
[FAILED] Both models failed. Total time: 47.82s
Primary error: timeout
Fallback error: 429 RESOURCE_EXHAUSTEDLa API de Vertex AI tiene límites de rate. Cuando los alcanzábamos, tanto Pro como Flash fallaban. La tasa de éxito cayó al 75% – inaceptable para un evento en vivo.
4. El Misterioso Error «NoneType»
Entre los logs apareció un error críptico:
'NoneType' object is not iterableDespués de investigar, descubrimos que ocasionalmente la API devolvía una respuesta vacía – sin imagen, sin error explícito. Nuestro código intentaba iterar sobre response.parts que era None.
La Solución: Triple Regional Fallback
El Insight Clave
Si las quotas de Vertex AI son por región. Si us-central1 estaba saturado, europe-west1 podía tener capacidad disponible. Esto nos dio la idea del fallback regional.
Arquitectura Final
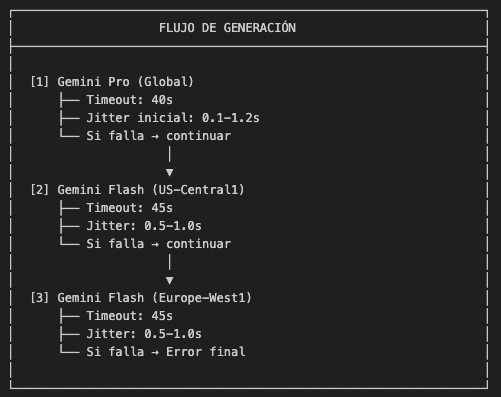
Implementación
class ImageGenerator:
def __init__(self):
# Tres clientes, tres regiones, tres pools de quota
self.client_pro = genai.Client(location="global")
self.client_flash_us = genai.Client(location="us-central1")
self.client_flash_eu = genai.Client(location="europe-west1")Manejo de Errores Transitorios
No todos los errores merecen un retry. Clasificamos los errores en:
Retryables (intentar siguiente región):
429 RESOURCE_EXHAUSTED– Quota agotada temporalmente503 ServiceUnavailable– Servicio temporalmente caídoEmpty response– API devolvió respuesta vacíaNoneType– Response.parts es None
No retryables (fallar inmediatamente):
- Safety filter violations
- Invalid request format
- Authentication errors
RETRYABLE_ERROR_MESSAGES = [
"ResourceExhausted", "ServiceUnavailable", "429", "503",
"quota", "rate limit", "empty response", "NoneType",
]
def is_retryable_error(exception: Exception) -> bool:
error_str = str(exception).lower()
return any(pattern.lower() in error_str
for pattern in RETRYABLE_ERROR_MESSAGES)El Fix del NoneType
Gracias a la monitorización permanente de los logs de Cloud Run identificamos errores en tiempo real que no tenían un origen en nuestra infraestructura sino en los propios fallos de respuesta del modelo. El error «NoneType» requirió una validación defensiva:
def _generate_single(self, client, model, contents, config):
response = client.models.generate_content(...)
# Validar ANTES de iterar
if response.parts is None or len(response.parts) == 0:
raise ValueError("Empty response from API (retryable)")
for part in response.parts:
if part.inline_data is not None:
return part.inline_data.data
raise ValueError("No image in response (retryable)")Resolución de Problemas en Tiempo Real
Nuestro modelo principal era el Gemini 3 Pro por su gran capacidad para generar imagenes tan fieles a la realidad, lo que se ajustaba a los requerimientos del proyecto. ¿Problema? el modelo estaba en preview y por lo tanto los limites de generación por minuto RPM son muy bajitos, con 8 stands generando imágenes al mismo tiempo esto era muy dificil de gestionar para sacar el máximo partido al Pro antes de pasar al 2.5.
En un primer momento la desición del cliente fue esperar a Pro lo máximo posible, se define darle tiempo hasta 120 segundos. Luego en el evento este criterio cambió:
El Día D: FITUR 2026
El evento comenzó a las 10:00. A las 10:30, el cliente reportó: «Las imágenes tardan mucho».
10:45 – Análisis de logs
gcloud logging read 'textPayload:"FAILED"' --limit=50Descubrimos que el timeout de Pro en 120 segundos era demasiado largo y ni aun asi llegaba a generar más con este modelo. Los usuarios esperaban casi 3 minutos adicionales cuando Pro fallaba.
11:00 – Hotfix #1: Reducir timeout
# Antes
timeout=120.0 # 120s - demasiado largo
# Después
timeout=40.0 # 40s - falla rápido, intenta Flash11:16 – Deploy en caliente
git commit -m "fix: reduce Pro timeout to 40s"
git push origin main # Trigger automático de Cloud Build11:20 – Monitoreo post-deploy
[Attempt 1/3] Primary model timed out after 40.00s
[Attempt 2/3] Falling back to Flash (US-Central1)
Fallback US model succeeded in 52.34s (total)
POST /generate HTTP/1.1" 200 OKEl sistema estaba recuperándose correctamente.
11:38 – Segundo problema detectado
[FAILED] All models failed. Total time: 55.01s
1. Pro (Global): timeout
2. Flash (US): 429 RESOURCE_EXHAUSTED
3. Flash (EU): 429 RESOURCE_EXHAUSTEDAmbas regiones de Flash saturadas simultáneamente. Afortunadamente, fue un caso aislado. La tasa de éxito post-deploy subió al 94.4%.
Métricas Finales del Evento
| Métrica | Antes del Fix | Después del Fix |
|---|---|---|
| Tasa de éxito | 75.3% | 94.4% |
| Tiempo máximo de espera | ~250s | ~133s |
| Intentos antes de éxito | 2 | 3 (regional) |
Lecciones Aprendidas
1. Diseña para el Fallo
En sistemas distribuidos, el fallo no es una excepción – es la norma. Cada componente externo (APIs, redes, servicios) fallará eventualmente. El sistema debe seguir funcionando.
«Everything fails, all the time»
Werner Vogels, CTO de AWS
2. Observabilidad desde el Día Uno
Los logs estructurados nos salvaron. Poder filtrar por [Attempt 1/3], [FAILED], o 429 hizo la diferencia entre resolver el problema en minutos vs. horas.
logger.info(f"[Attempt {attempt}/3] Falling back to: {model} ({region})")3. Jitter: El Héroe Silencioso
Un random.uniform(0.5, 1.0) de delay parece insignificante, pero evita avalanchas de requests. Es la diferencia entre 8 totems compitiendo por recursos y 8 totems colaborando.
4. Timeouts Agresivos > Reintentos Infinitos
Es mejor fallar rápido e intentar una alternativa que esperar eternamente por la respuesta «perfecta». El usuario prefiere una imagen en 50 segundos que ninguna imagen en 3 minutos.
El FITUR IA en números
FotoIA demostró que es posible construir sistemas de IA generativa robustos para entornos de alta demanda. Las claves fueron:
- Arquitectura resiliente: Múltiples modelos, múltiples regiones, múltiples oportunidades de éxito
- Observabilidad: Logs que cuentan una historia, no solo datos
- Iteración rápida: CI/CD que permite hotfixes en minutos
- Pragmatismo: A veces «bueno y rápido» supera a «perfecto y lento»
El stand de la Comunidad Valenciana fue uno de los más visitados de FITUR 2026. Miles de visitantes se llevaron a casa una foto única – ellos mismos, integrados por IA en los paisajes más hermosos del Mediterráneo. En concreto:
Las fotos generados por la IA, desglosada por días del Fitur, han sido:
- Dia 21: 353
- Dia 22: 321
- Dia 23: 431
- Dia 24: 1228
- Dia 25: 606
El coste total del proyecto en Google para la generación de imágenes fue de 486,76 €
Un caso de éxito que me ha dejado la certeza de que se pueden generar sistemas robustos haciendo vivecoding eficiente.