La inteligencia artificial generativa continúa su rápida evolución, y el reciente anuncio de Mistral AI con su serie «Mistral 3» marca un hito significativo en este panorama dinámico. Este lanzamiento, que incluye el modelo de lenguaje grande (LLM) propietario Mistral Large 3 y una familia de modelos más pequeños, Ministral (disponibles en 3B, 8B y 14B parámetros con pesos abiertos bajo licencia Apache 2.0), no solo refuerza la posición de Mistral AI en el mercado, sino que también ofrece nuevas oportunidades y desafíos para desarrolladores, arquitectos y CTOs que buscan implementar soluciones de IA en producción.
Este artículo profundiza en las implicaciones técnicas de la serie Mistral 3, analizando sus características, el impacto de los modelos de pesos abiertos y las estrategias prácticas para su implementación en entornos productivos, considerando el contexto competitivo actual y las decisiones arquitectónicas clave.
La serie Mistral 3: un vistazo técnico
Mistral AI ha consolidado su reputación por desarrollar modelos eficientes y de alto rendimiento. La serie Mistral 3 representa la próxima generación de esta línea, introduciendo mejoras en capacidad y eficiencia.
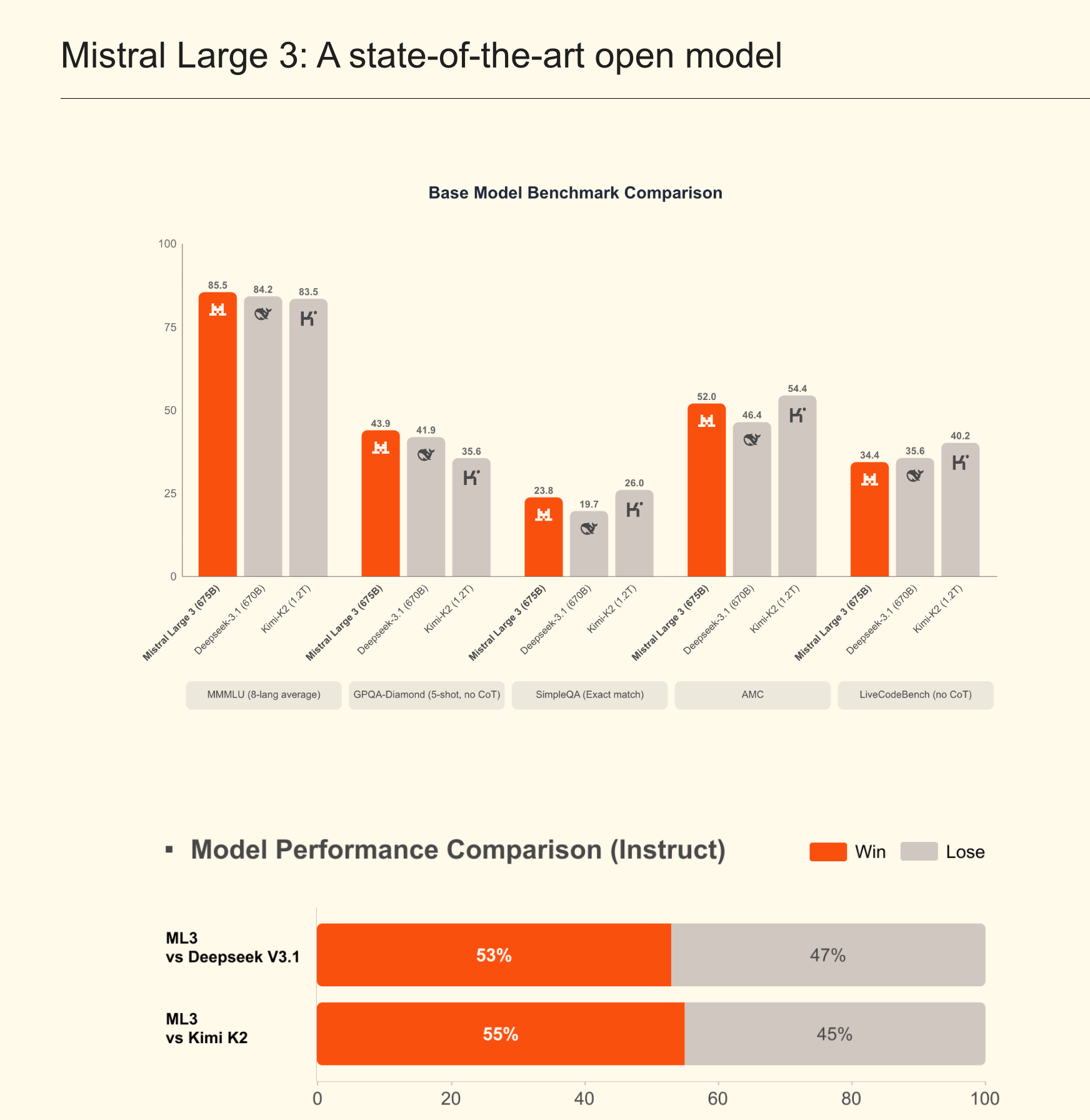
Mistral Large 3: el buque insignia propietario
Mistral Large 3 se posiciona como el modelo más potente de la compañía, diseñado para tareas complejas que requieren una comprensión contextual profunda, razonamiento avanzado y generación de texto de alta calidad. Si bien los detalles específicos de su arquitectura y los benchmarks públicos aún están emergiendo, se espera que este modelo compita directamente con otros LLMs de vanguardia como GPT-4, Claude 3 y Gemini Ultra.
Como modelo propietario, Mistral Large 3 se accede generalmente a través de APIs, lo que simplifica su integración pero implica una dependencia del proveedor y un modelo de precios basado en el uso. Sus principales casos de uso suelen incluir:
- Generación de contenido de alta calidad: Creación de artículos, resúmenes ejecutivos, código complejo.
- Análisis de datos avanzados: Extracción de información de documentos extensos, análisis de sentimientos, clasificación.
- Asistentes conversacionales inteligentes: Agentes de soporte al cliente o asistentes de programación que requieren una comprensión matizada y respuestas coherentes.
Ministral: la apuesta por los pesos abiertos
El aspecto más disruptivo de este lanzamiento es la familia Ministral, que incluye modelos de 3B, 8B y 14B parámetros, distribuidos con pesos abiertos bajo la licencia Apache 2.0. Esta decisión estratégica tiene profundas implicaciones técnicas y de negocio.
La licencia Apache 2.0 es altamente permisiva, permitiendo el uso comercial, la modificación, la distribución y la sublicencia de los modelos. Esto elimina muchas de las restricciones que a menudo acompañan a otras licencias de modelos de «código abierto» (como las licencias de Llama), que pueden limitar el uso comercial a gran escala o requerir la publicación de modificaciones.
Las características de los modelos Ministral sugieren diferentes aplicaciones:
- Ministral 3B: Ideal para inferencia en el borde (edge computing), dispositivos móviles o aplicaciones de baja latencia donde los recursos computacionales son limitados. Su tamaño reducido permite una mayor eficiencia energética y tiempos de respuesta más rápidos.
- Ministral 8B: Un equilibrio entre rendimiento y eficiencia. Adecuado para tareas de propósito general que requieren más capacidad que el 3B, pero sin la necesidad de los recursos del 14B. Puede ser una excelente opción para aplicaciones de chat, resúmenes cortos o generación de código simple.
- Ministral 14B: El modelo de pesos abiertos más grande de la serie, ofreciendo capacidades más avanzadas para tareas que demandan mayor comprensión y generación de texto más elaborada, manteniendo la flexibilidad de los pesos abiertos. Compite en un segmento donde Llama 3 8B y otros modelos de tamaño similar son fuertes.
La disponibilidad de pesos abiertos es un catalizador para la innovación, permitiendo a las empresas y desarrolladores personalizar los modelos, controlar sus datos y optimizar los costos de una manera que los modelos propietarios no pueden ofrecer.
Implicaciones técnicas de los modelos de pesos abiertos (Ministral)
La elección de un LLM de pesos abiertos como Ministral para producción conlleva una serie de ventajas técnicas y consideraciones estratégicas fundamentales.
Flexibilidad y personalización avanzada
Los modelos de pesos abiertos permiten un nivel de personalización inalcanzable con las APIs de modelos propietarios. Los desarrolladores pueden realizar fine-tuning (ajuste fino) de los modelos Ministral en conjuntos de datos específicos de su dominio o empresa. Esto mejora drásticamente la relevancia, precisión y el tono de las respuestas del modelo, reduciendo las «alucinaciones» y adaptándolo a la terminología interna.
Técnicas como LoRA (Low-Rank Adaptation) o QLoRA (Quantized LoRA) son particularmente útiles para esto, ya que permiten ajustar solo una pequeña fracción de los parámetros del modelo, reduciendo significativamente los requisitos de hardware y tiempo para el entrenamiento.
Control y soberanía de datos
Al ejecutar un modelo de pesos abiertos en infraestructura propia (on-premise) o en una Virtual Private Cloud (VPC) dedicada, las organizaciones mantienen un control total sobre sus datos. Esto es crítico para sectores con estrictas regulaciones de privacidad y seguridad, como finanzas, salud o gobierno. No se envían datos sensibles a terceros a través de APIs, lo que simplifica el cumplimiento normativo (GDPR, HIPAA, etc.) y reduce el riesgo de filtraciones.
Optimización de costos a largo plazo
Aunque la inversión inicial en infraestructura y talento para gestionar modelos de pesos abiertos puede ser mayor, los costos operativos a largo plazo pueden ser significativamente más bajos. Se elimina la dependencia de tarifas por token de APIs comerciales, lo que permite una mayor previsibilidad de costos y escalabilidad sin aumentos exponenciales. Para cargas de trabajo intensivas, ejecutar modelos en hardware propio o instanciado puede ser mucho más económico que pagar por cada inferencia a un proveedor externo.
Transparencia y auditabilidad
La licencia Apache 2.0 y la disponibilidad de los pesos permiten a los equipos de ingeniería inspeccionar el modelo, comprender mejor su comportamiento y auditarlo para sesgos o vulnerabilidades. Esta transparencia es invaluable para la confianza en sistemas de IA críticos y para la investigación de seguridad.
Estrategias de implementación de LLMs de pesos abiertos en producción
La puesta en marcha de modelos como Ministral en producción requiere una planificación cuidadosa y la aplicación de técnicas avanzadas para asegurar rendimiento, escalabilidad y eficiencia.
Selección del modelo adecuado para el caso de uso
La elección entre Ministral 3B, 8B o 14B depende directamente de los requisitos del caso de uso:
- Ministral 3B: Ideal para aplicaciones de baja latencia, como asistentes de teclado inteligentes, compresión de texto en tiempo real, o funciones simples de clasificación/extracción de entidades en el borde. Su huella de memoria es mínima.
- Ministral 8B: Un punto óptimo para muchas aplicaciones empresariales. Puede manejar tareas de generación de texto más complejas, resúmenes, traducción o como componente central en sistemas de respuesta a preguntas (Q&A) basados en RAG. Requiere menos recursos que el 14B pero ofrece una mejora sustancial sobre el 3B.
- Ministral 14B: Para tareas que exigen la máxima capacidad de razonamiento y generación de texto entre los modelos de pesos abiertos de Ministral, como la creación de contenido creativo, redacción de código o análisis de documentos largos.
La decisión debe basarse en un equilibrio entre la calidad de la salida requerida, la latencia aceptable, los costos de inferencia y los recursos de hardware disponibles.
Fine-tuning y RAG: potenciando la relevancia
Para que los LLMs sean realmente útiles en un contexto empresarial, a menudo se combinan con técnicas de Retrieval Augmented Generation (RAG) y fine-tuning.
- Indexación: Chunking de documentos empresariales y creación de embeddings vectoriales.
- Recuperación: Dada una consulta, se buscan los chunks más relevantes en la base de datos vectorial.
- Generación: El LLM recibe la consulta original y los chunks recuperados como contexto para generar una respuesta informada.
- RAG: Permite al modelo acceder a una base de conocimientos externa y actualizada para generar respuestas. Esto es crucial para mantener la información fáctica y reducir las alucinaciones.
- Fine-tuning: Complementa RAG al adaptar el modelo a un estilo, formato o vocabulario específico. Mientras RAG proporciona los hechos, el fine-tuning asegura que el modelo hable el «idioma» de la empresa y siga las directrices internas. Puede ser aplicado al modelo base o a la capa de recuperación del sistema RAG.
Optimización de inferencia para producción
La inferencia de LLMs es computacionalmente intensiva. Para los modelos Ministral en producción, es esencial aplicar técnicas de optimización:
- Cuantificación: Reduce el tamaño del modelo y los requisitos de memoria al representar los pesos con menor precisión (e.g., de FP16 a INT8 o INT4). Técnicas como AWQ (Activation-aware Weight Quantization) o GPTQ pueden reducir drásticamente el uso de VRAM con una mínima pérdida de rendimiento.
- Compilación de modelos: Herramientas como TorchInductor (PyTorch 2.0), ONNX Runtime o TensorRT pueden compilar los modelos para hardware específico (GPUs NVIDIA, CPUs) optimizando el grafo computacional y las operaciones.
- Batching dinámico: Agrupa múltiples solicitudes de inferencia en un solo lote para aprovechar la paralelización de las GPUs, mejorando el rendimiento general (throughput) a costa de una posible ligera latencia adicional por solicitud individual.
- Frameworks de inferencia optimizados: Soluciones como vLLM, Text Generation Inference (TGI) de Hugging Face, o Ray Serve están diseñadas específicamente para servir LLMs de manera eficiente, gestionando el batching, la paginación de claves/valores (KV cache) y otras optimizaciones.
Despliegue y escalabilidad
El despliegue de modelos de pesos abiertos en producción puede realizarse en diversas plataformas:
- Contenedores y orquestación: Docker y Kubernetes son la base para despliegues escalables. Un servicio de inferencia de LLM se puede empaquetar en un contenedor y escalar horizontalmente según la demanda, utilizando GPUs en los nodos de Kubernetes.
- Plataformas de ML en la nube: Servicios como Amazon SageMaker, Azure Machine Learning o Google Cloud Vertex AI ofrecen entornos gestionados para el despliegue de modelos, incluyendo instancias con GPUs y herramientas para el escalado automático.
- Serveless (para modelos pequeños): Para Ministral 3B, el despliegue en funciones serverless (AWS Lambda, Azure Functions, Google Cloud Functions) con GPUs adjuntas (si disponibles) podría ser una opción para cargas de trabajo esporádicas, minimizando los costos de infraestructura o el tiempo de inactividad. Sin embargo, los tiempos de «cold start» pueden ser una consideración.
- Hardware dedicado: Para cargas de trabajo muy elevadas o requisitos de baja latencia extrema, la inversión en hardware GPU dedicado (NVIDIA A100/H100) on-premise puede ser justificada.
Monitoreo y observabilidad
Una vez desplegados, los modelos requieren un monitoreo continuo. Esto incluye:
- Métricas de rendimiento: Latencia (tiempo por token, tiempo total), throughput (solicitudes por segundo), utilización de GPU/CPU, memoria.
- Métricas de calidad: Evaluación de la calidad de las respuestas (relevancia, coherencia, seguridad) utilizando métricas automáticas o evaluación humana.
- Detección de sesgos y alucinaciones: Implementar sistemas para identificar y mitigar comportamientos no deseados del modelo.
- Integración con sistemas de logging y tracing: Para depurar problemas y entender el flujo de las solicitudes.
Panorama competitivo y posicionamiento de Mistral AI
El lanzamiento de Mistral 3 se produce en un entorno de alta competencia, donde la innovación es constante. La mención de Deepseek V3.2, que ha logrado una notable posición en rankings de modelos abiertos, subraya la intensidad de esta carrera.
Mistral AI se ha posicionado como un jugador clave, especialmente en Europa, ofreciendo una alternativa robusta a los modelos de grandes corporaciones estadounidenses. Su estrategia de combinar modelos propietarios de alto rendimiento (Mistral Large 3) con una sólida oferta de pesos abiertos (Ministral) es inteligente. Esto les permite captar clientes que valoran la facilidad de uso y el rendimiento de las APIs, al mismo tiempo que atraen a aquellos que priorizan la flexibilidad, el control y la soberanía de datos que ofrecen los modelos de pesos abiertos.
La significativa ronda de financiación de 1.700 millones de dólares, valorando a Mistral AI en 11.700 millones de dólares, demuestra la confianza del mercado en su visión y capacidad de ejecución. Esta inyección de capital es crucial para sostener la intensa investigación y desarrollo necesaria para mantenerse competitivo en el espacio de los LLMs, que requiere enormes recursos computacionales y talento de ingeniería.
El éxito de Mistral y otros actores como Deepseek, Llama y Falcon, impulsa un ecosistema de IA más diverso y competitivo, beneficiando a los usuarios finales al ofrecer más opciones y fomentar la innovación a través de la competencia.
Consideraciones para arquitectos y CTOs
Para los líderes técnicos, la aparición de la serie Mistral 3 y el panorama general de los LLMs plantean decisiones estratégicas:
- Balance entre modelos propietarios y open-source: La decisión de usar un modelo propietario (como Mistral Large 3) o uno de pesos abiertos (como Ministral) no es mutuamente excluyente. Una estrategia híbrida podría implicar usar APIs propietarias para prototipos rápidos y tareas de bajo volumen, mientras se invierte en la integración y fine-tuning de modelos de pesos abiertos para cargas de trabajo críticas y de alto volumen, donde el control de datos y costos es primordial.
- Costo total de propiedad (TCO) vs. pago por uso: Es fundamental evaluar no solo el costo directo de los tokens, sino también el TCO que incluye infraestructura, personal de ingeniería, mantenimiento, cumplimiento y el riesgo asociado a la dependencia de un solo proveedor. Los modelos de pesos abiertos pueden tener un TCO más bajo a largo plazo para ciertas aplicaciones.
- Estrategias multi-modelo y multi-proveedor: Para mitigar riesgos y aprovechar las fortalezas de diferentes modelos, una arquitectura que permita intercambiar fácilmente LLMs (a través de abstracciones como LangChain o LlamaIndex) es una buena práctica. Esto permite experimentar con diferentes modelos para diferentes tareas o cambiar de proveedor si las condiciones del mercado cambian.
- Gestión de riesgos y cumplimiento normativo: La IA generativa introduce nuevos riesgos (alucinaciones, sesgos, seguridad). La capacidad de auditar y controlar los modelos de pesos abiertos puede ser una ventaja significativa para las organizaciones con altos requisitos de cumplimiento.
El lanzamiento de la serie Mistral 3, con su combinación de un potente modelo propietario y una familia de modelos de pesos abiertos bajo licencia Apache 2.0, marca un momento crucial en la evolución de la IA generativa. Para la comunidad de desarrolladores y las empresas, la disponibilidad de Ministral con pesos abiertos ofrece una oportunidad sin precedentes para construir soluciones de IA personalizadas, seguras y rentables.
Las implicaciones técnicas son profundas: desde la flexibilidad para el fine-tuning y la soberanía de datos, hasta la capacidad de optimizar la inferencia y el despliegue en infraestructuras controladas. Sin embargo, aprovechar al máximo estos modelos requiere experiencia en ingeniería de machine learning, incluyendo el dominio de técnicas de RAG, cuantificación, y plataformas de despliegue escalables.
Mistral AI no solo consolida su posición como un actor relevante en el panorama global de la IA, sino que también contribuye a un ecosistema más vibrante y competitivo, donde la innovación abierta y la personalización son cada vez más valoradas. La tendencia hacia modelos de pesos abiertos potentes y bien licenciados continuará democratizando el acceso a la IA avanzada, empoderando a más organizaciones para integrar esta tecnología transformadora en el corazón de sus operaciones.
📚 Referencias y Fuentes
Este artículo se ha elaborado consultando las siguientes fuentes: news.smol.ai

