El reciente anuncio de Gemini 3 Pro por parte de Google representa un avance significativo, posicionándose como un modelo de última generación (SOTA) que ha capturado la atención de la comunidad técnica global.
Este artículo explora las implicaciones técnicas y estratégicas del lanzamiento de Gemini 3 Pro, analizando su rendimiento, el impacto en la dinámica competitiva de los LLMs, y las consideraciones prácticas, especialmente en lo que respecta a la optimización de costos y la implementación en entornos de producción. Se abordará la importancia de las evaluaciones independientes y se ofrecerán perspectivas sobre cómo los profesionales de la IA pueden adaptar sus arquitecturas y estrategias para capitalizar estas innovaciones, manteniendo una visión orientada a resultados y la sostenibilidad a largo plazo.
Un nuevo líder en los benchmarks de LLMs
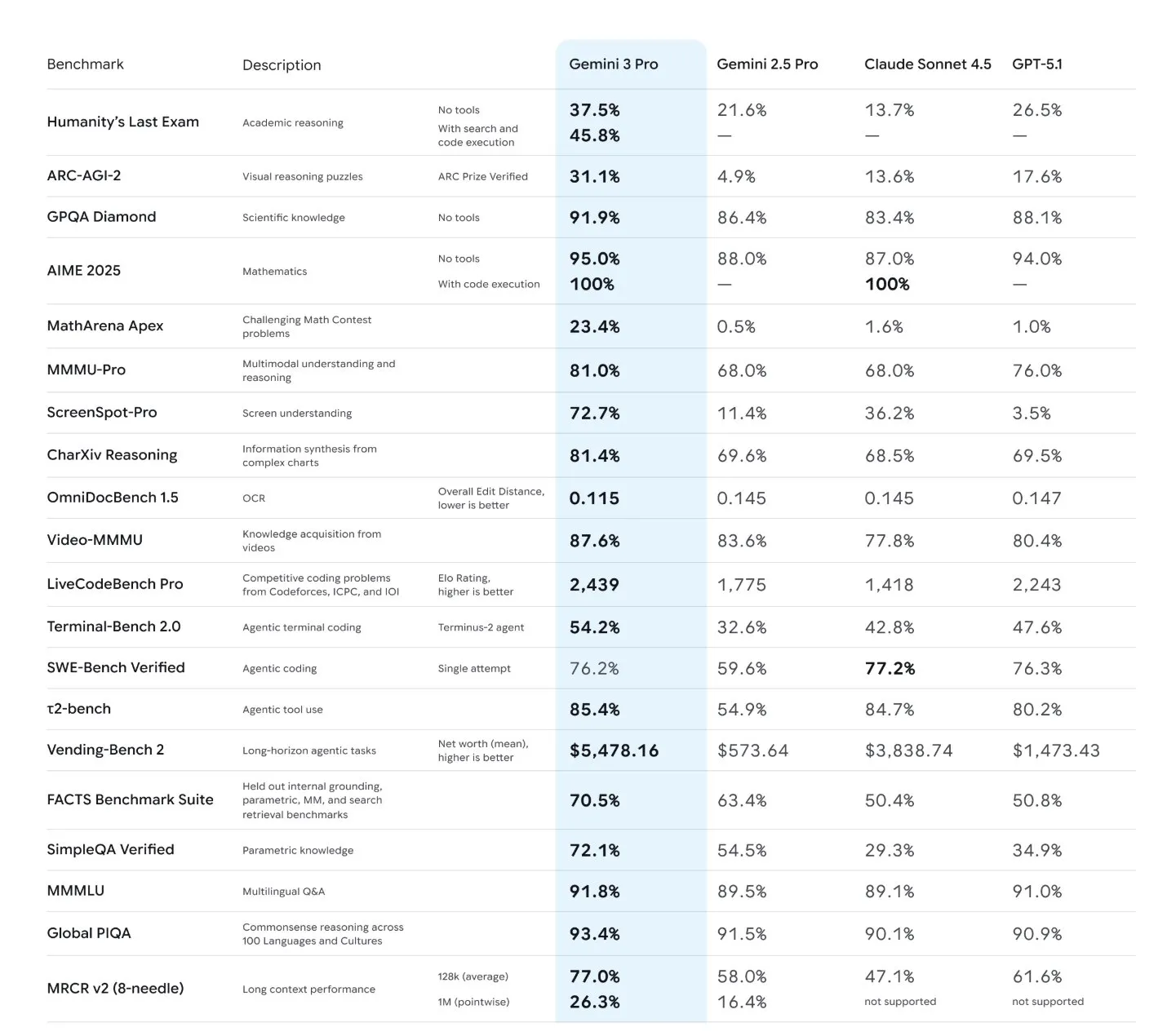
El lanzamiento de Gemini 3 Pro ha reconfigurado el liderazgo en el competitivo campo de los modelos de lenguaje de frontera. Según las evaluaciones iniciales y su posicionamiento en las principales tablas de clasificación de Arena, Gemini 3 Pro no solo supera a su predecesor, Gemini 2.5, sino que también ha demostrado un rendimiento superior frente a otros contendientes clave como Grok 4.1, Sonnet 4.5 y GPT-5.1. Este logro indica que Gemini 3 Pro ha alcanzado resultados SOTA en la mayoría de los benchmarks evaluados, lo que se traduce en capacidades mejoradas para una amplia gama de tareas.
El término «SOTA» (State-Of-The-Art) en este contexto implica que Gemini 3 Pro exhibe una comprensión del lenguaje más profunda, una capacidad de razonamiento más sofisticada y una habilidad para seguir instrucciones complejas con mayor precisión. Para desarrolladores y arquitectos, esto puede significar:
- Mejora en la coherencia y relevancia de las respuestas: Los modelos SOTA suelen generar contenido más pertinente y menos propenso a las «alucinaciones».
- Manejo de contextos más extensos y complejos: Una mayor ventana de contexto permite procesar y generar texto en escenarios que requieren una comprensión global de documentos extensos o interacciones conversacionales prolongadas.
- Razonamiento avanzado para tareas multimodales y agentes de IA: Si bien la información específica sobre la multimodalidad de Gemini 3 Pro no se detalla, la familia Gemini es conocida por sus capacidades multimodales. Un rendimiento SOTA en un modelo de frontera a menudo implica una mejor integración de diferentes tipos de datos (texto, imagen, audio, vídeo) y una capacidad superior para ejecutar tareas complejas que requieren múltiples pasos de razonamiento, fundamentales para el desarrollo de agentes de IA autónomos.
- Mayor eficiencia en el few-shot learning: La capacidad de aprender de pocos ejemplos se optimiza, reduciendo la necesidad de grandes volúmenes de datos de entrenamiento específicos para cada tarea.
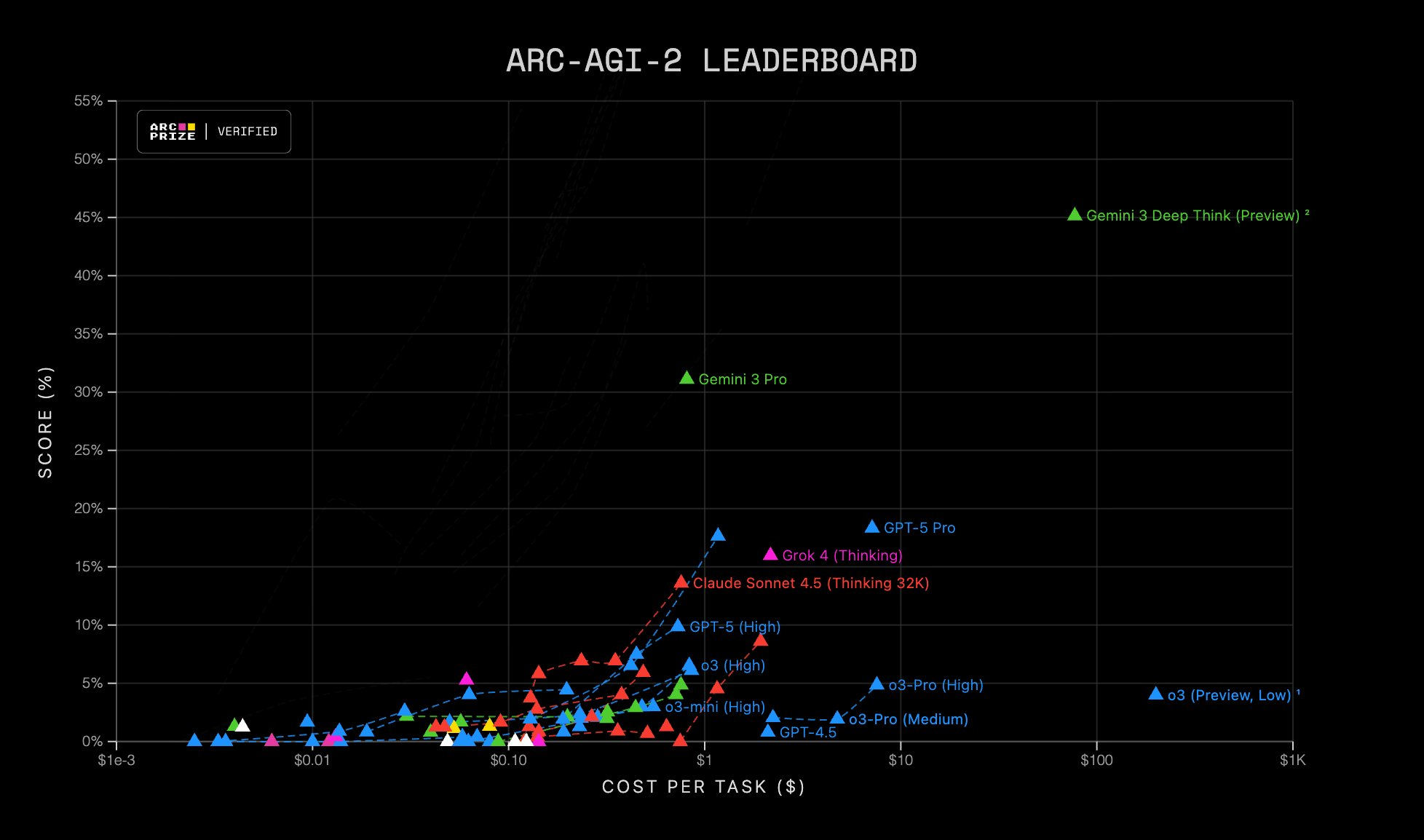
La credibilidad de estas afirmaciones de rendimiento se refuerza al citar evaluaciones independientes de terceros. Fuentes como Artificial Analysis, Vending Bench y ARC-AGI 2 son cruciales para validar de manera imparcial las capacidades de los modelos. Estas organizaciones realizan pruebas rigurosas en conjuntos de datos diversos y realistas, proporcionando una perspectiva objetiva que complementa los benchmarks internos de los proveedores. La comunidad técnica confía en estas evaluaciones para tomar decisiones informadas sobre la adopción de nuevos modelos.
Capacidades técnicas y escenarios de aplicación
Las mejoras en el rendimiento de Gemini 3 Pro abren nuevas avenidas para la implementación de soluciones de IA generativa avanzadas. Aunque los detalles específicos de la API y las características no se han desglosado en el resumen, la categoría de «modelo de frontera» sugiere un conjunto robusto de capacidades:
- Comprensión y generación de lenguaje natural mejoradas: Esto es fundamental para aplicaciones que requieren una interacción humana fluida, como chatbots avanzados, asistentes virtuales y sistemas de soporte al cliente automatizados. La capacidad de entender la intención del usuario y generar respuestas contextualmente relevantes es crítica.
- Razonamiento complejo para flujos de trabajo de agentes: Los agentes de IA, que involucran planificación, ejecución de herramientas y toma de decisiones, se benefician enormemente de modelos con capacidades de razonamiento superiores. Gemini 3 Pro podría potenciar agentes capaces de automatizar tareas complejas, desde la gestión de calendarios hasta la investigación de mercado.
- Extracción y resumen de información sofisticados: En entornos empresariales, la capacidad de procesar grandes volúmenes de documentos (informes, contratos, artículos científicos) y extraer información clave o generar resúmenes concisos es invaluable. Un modelo SOTA puede realizar estas tareas con mayor precisión y menos supervisión humana.
- Generación de código y análisis: Los desarrolladores y arquitectos pueden aprovechar Gemini 3 Pro para la generación asistida de código, la refactorización, la depuración o incluso la traducción de código entre lenguajes. Un modelo con un rendimiento superior puede producir código más robusto y funcional, acelerando el ciclo de desarrollo.
- Sistemas de Recuperación Aumentada por Generación (RAG) avanzados: Para aplicaciones RAG, donde la precisión y la relevancia de la información recuperada son primordiales, un modelo como Gemini 3 Pro puede mejorar significativamente la capacidad de sintetizar información de fuentes externas y generar respuestas bien fundamentadas, reduciendo las «alucinaciones» y aumentando la fiabilidad.
- Generación de contenido a escala: Empresas de medios, marketing y educación pueden utilizar este modelo para la creación automatizada de artículos, descripciones de productos, material didáctico y otros contenidos, manteniendo altos estándares de calidad y coherencia.
La integración de un modelo con estas características en una arquitectura de IA existente requiere una planificación cuidadosa, considerando la latencia de la inferencia, el throughput y la compatibilidad con el stack tecnológico actual. La versatilidad de Gemini 3 Pro sugiere que puede ser un componente central en una amplia gama de soluciones innovadoras, siempre que se justifique su adopción desde una perspectiva de rendimiento y costo.
Rendimiento superior frente a la economía de la IA
La adopción de modelos de IA de frontera no solo se rige por su rendimiento técnico, sino también por su viabilidad económica. El anuncio de que Gemini 3 Pro presenta un incremento del 60% en su precio respecto a Gemini 2.5 introduce una variable crítica para la planificación de costos y la toma de decisiones en proyectos de IA. Para CTOs y arquitectos, esta diferencia de precio no es trivial y requiere un análisis detallado del Retorno de la Inversión (ROI) potencial.
El costo de un LLM se compone de varios factores, incluyendo el precio por token de entrada y salida, la latencia de inferencia (que afecta la experiencia del usuario y la capacidad de procesamiento), y el throughput (cantidad de solicitudes procesadas por unidad de tiempo). Un modelo más caro por token puede, en ciertos escenarios, justificar su precio si ofrece una calidad de salida significativamente superior que reduce la necesidad de post-procesamiento humano, mejora la satisfacción del cliente o desbloquea nuevas capacidades de negocio.
Considerar el Costo Total de Propiedad (TCO) es fundamental. Este incluye no solo el costo directo de la API, sino también los costos de ingeniería asociados a la integración, el monitoreo, la gestión de errores y la optimización del rendimiento. Un modelo que requiere menos prompt engineering o menos iteraciones para alcanzar la calidad deseada podría, paradójicamente, resultar más económico a largo plazo, a pesar de un costo por token más alto.
Metodologías para una evaluación costo-beneficio objetiva
Para evaluar si el rendimiento superior de Gemini 3 Pro justifica su costo, los equipos de ingeniería y liderazgo deben implementar metodologías de evaluación costo-beneficio robustas:
- Definición de métricas de negocio y técnicas: Antes de cualquier comparación, es crucial establecer qué métricas son prioritarias.
- Métricas de negocio: Aumento de la eficiencia operativa (ej. reducción del tiempo de respuesta del servicio al cliente), mejora en la calidad del producto (ej. menos errores en contenido generado), incremento en la satisfacción del usuario, o impacto directo en ingresos.
- Métricas técnicas: Costo por token (input/output), latencia promedio y percentiles, throughput máximo, precisión, recall, F1-score en tareas específicas, Human Evaluation Score (HES).
- Análisis de escenarios:
- Escenarios de alto valor: En aplicaciones críticas donde la precisión y la calidad son imperativas (ej. asistencia médica, análisis financiero, generación de código para producción), el costo adicional de Gemini 3 Pro podría estar justificado si reduce significativamente los errores o mejora la eficiencia de una manera que genere un valor sustancial. Por ejemplo, si un modelo de mayor calidad reduce en un 5% el tiempo de un ingeniero para revisar código generado, el ahorro en salarios podría superar el costo adicional del modelo.
- Escenarios de volumen y bajo valor unitario: Para tareas de alto volumen pero con menor impacto crítico (ej. generación de descripciones de productos de bajo valor, chatbots de soporte básico), un modelo con un costo por token más bajo, aunque con un rendimiento ligeramente inferior, podría ser la opción más rentable. La clave es determinar el umbral de calidad aceptable para cada caso de uso.
- Realizar pruebas A/B controladas: Implementar pruebas A/B con diferentes modelos (Gemini 3 Pro vs. Gemini 2.5 o competidores) en un subconjunto de tráfico de producción o en un entorno de staging. Monitorear las métricas de negocio y técnicas en paralelo para cuantificar el impacto real de cada modelo.
- Modelado financiero y ROI: Proyectar los costos operativos de cada modelo a lo largo del tiempo, considerando el volumen de uso esperado. Calcular el ROI esperado al cuantificar el valor de las mejoras de rendimiento. Por ejemplo, si Gemini 3 Pro mejora la tasa de conversión en un 2%, ¿cuánto valor adicional genera eso frente a su costo?
- Herramientas de monitoreo de costos: Utilizar herramientas de gestión de costos en la nube y plataformas de observabilidad específicas para LLMs (como LangSmith para LangChain, o soluciones personalizadas) para rastrear el uso de tokens y los gastos en tiempo real. Establecer alertas para desviaciones de presupuesto.
La decisión de adoptar Gemini 3 Pro, o cualquier modelo de frontera, debe ser el resultado de un análisis riguroso que equilibre la vanguardia tecnológica con la viabilidad económica y la estrategia de negocio.
Navegando el ecosistema de LLMs con evidencia
La velocidad a la que evolucionan los LLMs hace que la selección del modelo adecuado sea un desafío constante. Las afirmaciones de rendimiento de los proveedores, aunque valiosas, a menudo se basan en benchmarks internos que pueden no reflejar completamente el rendimiento en escenarios del mundo real o en conjuntos de datos específicos. Aquí es donde la evaluación independiente y el benchmarking continuo se vuelven indispensables para los profesionales de la IA.
Plataformas de evaluación pública, como LMArena (referida como «Arena» en el contexto), juegan un papel crucial al proporcionar un espacio transparente para comparar el rendimiento de diferentes modelos en una variedad de tareas y métricas. Estas plataformas permiten a la comunidad evaluar y clasificar modelos basándose en pruebas estandarizadas y, en muchos casos, en la retroalimentación de usuarios humanos.
Además de las plataformas públicas, organizaciones de terceros como Artificial Analysis, Vending Bench y ARC-AGI 2 ofrecen análisis más profundos y especializados. Estas entidades suelen emplear metodologías de evaluación rigurosas, incluyendo:
- Conjuntos de datos diversos y representativos: Asegurando que el modelo se pruebe en una amplia gama de dominios y estilos de lenguaje.
- Métricas de evaluación exhaustivas: Más allá de la precisión simple, se consideran aspectos como la coherencia, la relevancia, la seguridad, el sesgo y la robustez.
- Transparencia metodológica: Detallando cómo se realizan las pruebas, permitiendo la reproducibilidad y el escrutinio por parte de la comunidad.
- Enfoque en casos de uso específicos: Evaluando el rendimiento en escenarios que son particularmente relevantes para aplicaciones empresariales o de investigación.
Para los arquitectos y CTOs, confiar únicamente en las métricas del proveedor puede llevar a decisiones subóptimas. Las evaluaciones independientes proporcionan una capa de validación crucial, ayudando a mitigar riesgos y a seleccionar modelos que realmente se ajusten a los requisitos técnicos y de negocio.
Construyendo un marco de evaluación interno para producción
La dependencia de evaluaciones externas, aunque necesaria, no es suficiente para garantizar el éxito en producción. Los equipos de ingeniería deben establecer sus propios marcos de evaluación y monitoreo continuos para asegurar que los LLMs seleccionados se desempeñen de manera óptima en sus contextos específicos.
Un marco de evaluación interno efectivo debe incluir:
- Definición de objetivos claros y específicos: Antes de evaluar, ¿qué se espera lograr con el LLM? ¿Cuáles son las métricas de éxito para la aplicación particular? Esto puede variar desde la reducción de la tasa de error en un resumen hasta la mejora del engagement del usuario en un chatbot.
- Creación de un «golden dataset» representativo: Un conjunto de datos de evaluación cuidadosamente curado, que refleje las características y la complejidad de los datos de producción. Este dataset debe incluir casos límite, ejemplos desafiantes y escenarios críticos para el negocio.
- Implementación de pruebas automatizadas y manuales:
- Automatizadas: Utilizar métricas basadas en embeddings (como ROUGE, BLEU, o similitud semántica), pruebas de regresión para asegurar que las actualizaciones del modelo no introduzcan nuevos errores, y pruebas de robustez frente a entradas adversarias.
- Manuales: Incorporar la evaluación humana para aspectos cualitativos como la coherencia, el tono, la creatividad y la adecuación cultural, que son difíciles de capturar con métricas automatizadas.
- Integración con pipelines CI/CD: Asegurar que cada actualización de un modelo (ya sea un nuevo modelo base o un fine-tuning interno) pase por el marco de evaluación. Esto permite una validación continua y la detección temprana de regresiones de rendimiento.
- Herramientas de observabilidad para LLMs: Implementar soluciones que permitan:
- Monitoreo del rendimiento: Latencia, throughput, tasa de errores de la API.
- Trazabilidad de la inferencia: Registrar entradas, salidas, parámetros del modelo y cualquier paso intermedio (en el caso de agentes).
- Análisis de prompts y respuestas: Identificar patrones en las entradas que causan bajo rendimiento o alucinaciones.
- Recopilación de feedback: Permitir a los usuarios humanos proporcionar retroalimentación directa sobre la calidad de las respuestas del modelo. Herramientas como LangSmith, Phoenix o plataformas personalizadas son valiosas en este aspecto.
- Estrategias de A/B testing: Para comparar el rendimiento de diferentes modelos o configuraciones de prompts en entornos de producción, el A/B testing es esencial. Permite una evaluación empírica del impacto real en los usuarios y las métricas de negocio.
La implementación de un marco de evaluación robusto y continuo es una inversión estratégica que permite a las organizaciones tomar decisiones basadas en datos, optimizar la selección de modelos y garantizar la calidad y fiabilidad de sus soluciones de IA generativa a medida que el panorama tecnológico sigue evolucionando.
Integración de modelos de frontera en arquitecturas existentes
La clave para una integración exitosa radica en el diseño de arquitecturas flexibles que puedan adaptarse a la rápida evolución del ecosistema de LLMs.
- Abstracción de modelos y APIs: Es fundamental desacoplar la lógica de negocio de la implementación específica del LLM. Esto se logra mediante capas de abstracción que encapsulan las llamadas a la API de diferentes proveedores (Google, OpenAI, Anthropic, etc.). Herramientas como LiteLLM o la creación de un proxy de modelo interno permiten a los desarrolladores cambiar fácilmente entre modelos con cambios mínimos en el código de la aplicación. Esta estrategia mitiga el riesgo de vendor lock-in y facilita la experimentación con nuevos modelos a medida que aparecen.
- Arquitectura de microservicios y modularidad: Diseñar los componentes del sistema como microservicios permite una mayor modularidad y escalabilidad. Cada servicio puede ser responsable de una función específica (ej. prompt engineering, gestión de memoria de conversación, integración RAG, llamadas a LLMs), lo que facilita la actualización o el reemplazo de componentes individuales sin afectar a todo el sistema.
- Gestión de versiones y entornos: Implementar una gestión rigurosa de versiones para los prompts, los modelos y las configuraciones. Utilizar entornos de desarrollo, staging y producción bien definidos para probar y desplegar cambios de manera segura.
- Consideraciones de datos y seguridad: Al integrar APIs de modelos externos, es crucial implementar prácticas robustas de gobernanza de datos. Esto incluye la anonimización de datos sensibles antes de enviarlos a la API, el cumplimiento de regulaciones de privacidad (GDPR, CCPA) y la evaluación de las políticas de uso de datos de cada proveedor de LLM. La seguridad de las claves API y la gestión de accesos también son primordiales.
Escalabilidad, resiliencia y observabilidad
La integración de LLMs de frontera, especialmente aquellos que operan como servicios externos, introduce requisitos específicos en términos de escalabilidad, resiliencia y observabilidad.
- Escalabilidad:
- Gestión de cuotas y límites de rate: Los proveedores de LLMs suelen imponer límites de tasa de llamadas. La arquitectura debe incluir mecanismos de rate limiting y backoff para gestionar estas cuotas y evitar interrupciones del servicio.
- Procesamiento asíncrono y colas de mensajes: Para cargas de trabajo intensivas o tareas que no requieren una respuesta inmediata, el procesamiento asíncrono con colas de mensajes (ej. Kafka, RabbitMQ, SQS) puede desacoplar la generación de respuestas LLM del flujo principal de la aplicación, mejorando la escalabilidad y la capacidad de respuesta.
- Caché inteligente: Implementar capas de caché para respuestas repetitivas o para resultados de llamadas a LLMs que no cambian con frecuencia. Esto reduce la latencia y el costo al minimizar las llamadas redundantes a la API.
- Resiliencia:
- Mecanismos de fallback: Diseñar el sistema para manejar fallos de la API del LLM. Esto puede incluir el uso de un modelo de respaldo más pequeño o local, respuestas predefinidas, o notificaciones al usuario sobre una disponibilidad temporalmente reducida.
- Circuit breakers y reintentos: Implementar patrones de circuit breaker para detectar y aislar servicios externos que están fallando, evitando que las fallas en cascada afecten a todo el sistema. Los mecanismos de reintento con jitter y exponential backoff son esenciales para manejar fallos transitorios.
- Monitorización proactiva: Utilizar alertas para detectar problemas de rendimiento o disponibilidad de la API del LLM antes de que afecten a los usuarios.
- Observabilidad:
- Logging y tracing: Recopilar logs detallados de todas las interacciones con el LLM, incluyendo prompts, respuestas, tiempos de latencia y costos por token. Implementar tracing distribuido para seguir el flujo de solicitudes a través de múltiples servicios y el LLM, facilitando la depuración y el análisis de rendimiento.
- Métricas de rendimiento y costo: Monitorear métricas clave como el número de llamadas a la API, la latencia promedio, el throughput, la tasa de errores y, crucialmente, el costo acumulado por modelo y por caso de uso. Esto permite una optimización continua y una gestión financiera proactiva.
- Visualización y dashboards: Crear dashboards personalizados que presenten una visión holística del rendimiento, la salud y los costos de los sistemas de IA generativa, permitiendo a los equipos identificar rápidamente anomalías y tomar decisiones informadas.
La integración de modelos de frontera en arquitecturas de producción exige un enfoque holístico que vaya más allá de la mera elección del modelo. Un diseño cuidadoso centrado en la flexibilidad, la eficiencia y la robustez es fundamental para construir sistemas de IA generativa que puedan escalar y evolucionar con las demandas del negocio y el avance tecnológico.
Tendencias futuras y nuestra visión
El anuncio de Gemini 3 Pro y la constante competencia en el ámbito de los LLMs de frontera subrayan varias tendencias clave que continuarán moldeando el futuro de la IA generativa:
- Innovación continua y democratización del acceso: La carrera por el modelo más potente seguirá impulsando la investigación y el desarrollo. A medida que estos modelos maduran, es probable que se observe una democratización de sus capacidades a través de APIs más accesibles y herramientas de desarrollo mejoradas.
- Enfoque en la eficiencia y la especialización: Si bien los modelos de frontera generales son impresionantes, la necesidad de optimización de costos y rendimiento impulsará el desarrollo de modelos más pequeños y especializados (SLMs – Small Language Models) para tareas específicas, así como técnicas de fine-tuning y prompt engineering más avanzadas.
- El auge de los sistemas de agentes y la multimodalidad: La capacidad de los LLMs para razonar y planificar es fundamental para el desarrollo de agentes de IA autónomos. La integración de capacidades multimodales permitirá a estos agentes interactuar con el mundo de manera más rica, procesando y generando información a través de diferentes formatos.
- MLOps para LLMs (LLMOps) como disciplina crítica: La complejidad de gestionar, evaluar, desplegar y monitorear LLMs en producción hará que las prácticas de MLOps adaptadas a estos modelos sean aún más cruciales. Esto incluye la gestión de prompts, el versionado de modelos, el monitoreo del rendimiento y el costo, y la implementación de ciclos de vida de desarrollo continuo.
Adaptación estratégica en la era de la IA
El lanzamiento de Gemini 3 Pro es un recordatorio potente de la rápida evolución y la intensa competencia en el campo de la IA generativa. Este nuevo modelo de frontera ofrece capacidades de vanguardia que prometen transformar una multitud de aplicaciones, pero también presenta el desafío de un costo incrementado que exige una evaluación económica rigurosa.
Para los profesionales de la tecnología, la clave del éxito en esta era de la IA radica en la adaptación estratégica. Esto implica:
- Mantenerse al día con los últimos avances tecnológicos y las evaluaciones de rendimiento de terceros.
- Implementar marcos de evaluación objetivos y continuos que equilibren el rendimiento técnico con las métricas de negocio y los costos operativos.
- Diseñar arquitecturas de sistemas de IA flexibles y resilientes que puedan integrar y gestionar múltiples modelos de manera eficiente, garantizando escalabilidad y observabilidad.
- Tomar decisiones basadas en datos que consideren no solo las capacidades individuales de un modelo, sino su impacto holístico en la organización y sus objetivos estratégicos.
La inversión en una sólida estrategia de MLOps y en la construcción de equipos capaces de gestionar la complejidad de los LLMs de frontera será fundamental para capitalizar plenamente el potencial de la IA generativa. En GHEN Digital, creemos que la comprensión profunda de estos trade-offs y la implementación de soluciones prácticas son esenciales para construir el futuro de la inteligencia artificial.
📚 Referencias y Fuentes
Este artículo se ha elaborado consultando las siguientes fuentes: news.smol.ai

