Para aquellos que nos iniciamos en los modelos opensource que ofrece Hugging Face les dejo esta guia a modo de introducción en la que verán básicamente cómo elegir un modelo, los criterios de tareas y licencias, el clonado de repositorios y la creación de un pipeline para conversar con un modelo pequeño desde nuestro ordenador. ¡Vamos allá!
Seleccionando un modelo
Para seleccionar un modelo desde este repositorio nos dirigimos a modelos.
Luego en el panel de la izquierda podremos elegir la tarea más acorde al proyecto que estamos construyendo. Digamos que, por ejemplo, queremos hacer una app para traducir al francés, entonces elegiremos text to speech, luego lenguage: French y podremos ver un listado de modelos entrenados en este sentido que bien podemos ordenar por los más descargados o los modelos en tendencia. Adicionalmente podemos ver en el apartado Licence información sobre los permitidos usos del modelo en nuestro proyecto, incluso si se permite su uso comercial, como es el caso de las licencias Apache 2.0
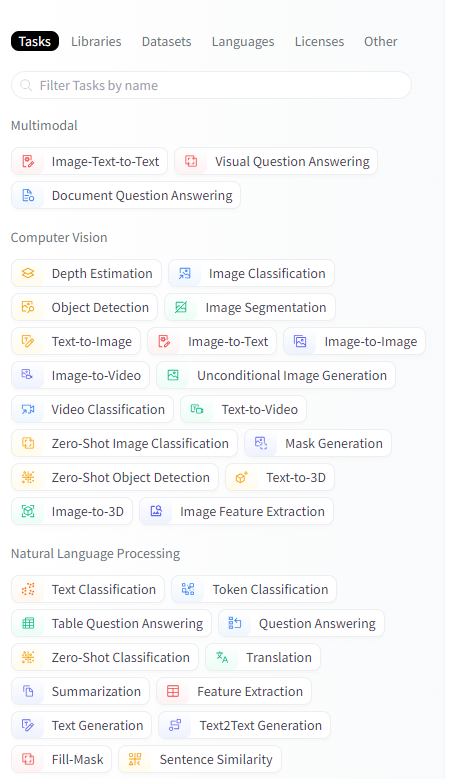
Si no tienes claro la tarea que debes escoger para tu proyecto la mejor manera de aproximarse a la respuesta se encuentra en Tasks. En esta página aprenderas sobre las distintas tareas en machine learning, demos, datasets, etc. Incluso ver dentro de la ficha de la tarea el modelo más utilizado para este fin.
Una vez dentro de la ficha de modelo podremos ver información sobre la cantidad de descargas en el último mes, cómo ha sido entrenado, etc.
Dentro de la información del tamaño del modelo podremos revisar si contamos con el hardware suficiente para descargar y ejecutar/entrenar al modelo seleccionado. Un truco para ver esto es entrar en «Files and versions» dentro de la ficha del modelo y mirar por ejemplo, en el archivo pytorch_model.bin donde figura el peso del modelo, multiplicando este valor por 1.2(20%) obtendremos la respuesta de la memoria de entrenamiento necesaria.

En el panel de la derecha veremos el botón «Use in Transformers», haciendo click aqui podrás obtener el código necesario para llamar al modelo dentro de tu proyecto de machine learning. Adicionalmente tienes acceso a documentación oficial.
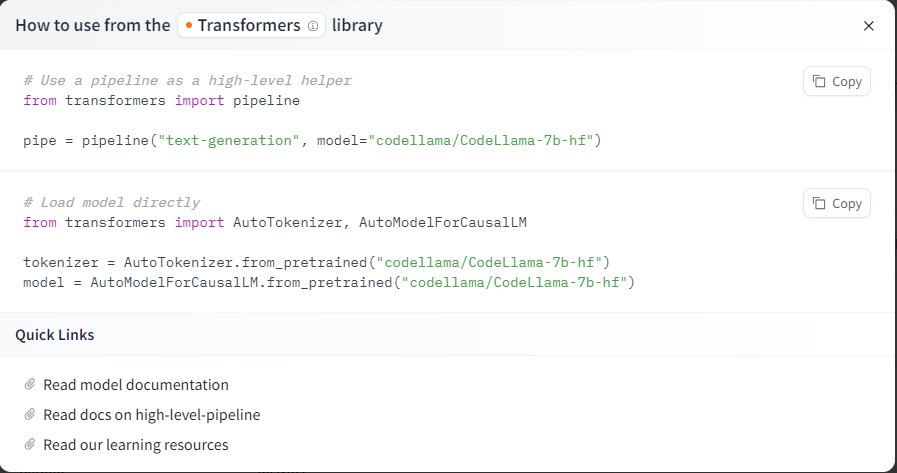
Es interesante conocer el dato de que esta llamada al modelo utiliza el Pipeline Objetc, el cual ofrece un alto nivel de abstracción para resolver tareas y nos permite olvidarnos de complejidades de pre-procesamiento de los inputs que el modelo espera, como ser la tokenización para modelos de texto o la normalización para modelos que trabajan con imágenes.
Natural Language Processing (NLP)
Comencemos con un ejemplo porque nada mejor que la práctica para aprender sobre machine learning. Dentro de tu IDE crea un entorno virtual para instalar las dependencias necesarias dentro del proyecto local y no a nivel global en tu ordenador(ya que podría ocasionar conflictos con otras dependencias del sistema y es una práctica recomendada).
Una vez dentro de tu entorno env ejecuta el comando pip install transformers para permitir el llamado a las librerias de Huggin Face.
#Here is some code that suppresses warning messages:
from transformers.utils import logging
logging.set_verbosity_error()
from transformers import pipeline
from transformers import Conversation
#Define the conversation pipeline
chatbot = pipeline(task="conversational",
model="./models/facebook/blenderbot-400M-distill")
user_message = """
What are some fun activities I can do in the winter?
"""
conversation = Conversation(user_message)
print(conversation)
conversation = chatbot(conversation)
print(conversation)
#Resultado:
Conversation id: b85215c5-a99c-4cbb-a31b-42dedf8f6f7f
user:
What are some fun activities I can do in the winter?
assistant: I like to go snowboarding in the winter. It's a lot of fun.Aquí hay información sobre el modelo que se utiliza en este ejemplo: https://huggingface.co/facebook/blenderbot-400M-distill
NOTA: la primera vez he obtenido un error al que le he dedicado toda la tarde porque necesitaba tener Tensorflow instalado como dependencia y un directorio llamado «models» dentro del proyecto con el repo del modelo.
Solución: pip install tensorflow + clonar el repo https://huggingface.co/facebook/blenderbot-400M-distill/tree/main en un directorio «models/facebook/»:
Puedes continuar la conversación con el modelo utilizando:
print(chatbot(Conversation(«What else do you recommend?»)))
Incluso agregar memoria a la conversación para que el modelo recuerde la pregunta anterior para dar su respuesta:
conversation.add_message(
{"role": "user",
"content": """
What else do you recommend?
"""
})
print(conversation)
conversation = chatbot(conversation)
print(conversation)Dado que este modelo es muy pequeño puede que las respuestas dejen mucho que desear, pero al menos hemos podido interactuar.
Tablas de clasificación
Puedes encontrar un ranking de los modelos de chatbot y Open LLM de la comunidad en estos tableros:
Dentro de los filtros podemos hacer cosas interesantes como encontrar los modelos pre-entrandos que han sido creados desde 0. Por los costos computacionales que eso implica los primeros resultados serán aquellos modelos de grandes empresas.
Dado que muchos profesionales son excepticos a este tablero se ha creado otro:
LMSYS Chatbot Arena Leaderboard
En este tablero recolecta más de 800.000 comparaciones humanas para clasificar los modelos.
El curso perfecto
Un curso perfecto para comenzar, gratuito y realizado por el equipo de Huggin Face en la plataforma especializada en Inteligencia Artificial: https://learn.deeplearning.ai/

