Hugging Face se ha convertido en la plataforma open source principal para compartir y utilizar modelos de aprendizaje profundo, en especial modelos de lenguaje de gran escala (LLMs) aunque los hay de todos los tamaños y para multiples tareas como ya desarrollé en Introducción a Hugging Face. Hoy vamos a explorar un repositorio de modelos, es decir los directorios que se encuentran dentro de cada modelo en esta plataforma para explicar su propósito. Aquí nos encontramos con varios archivos clave. Cada uno de estos archivos cumple un papel esencial en la arquitectura, configuración y ejecución del modelo. En este artículo, desglosaremos los archivos más comunes en los modelos de Hugging Face y explicaremos su propósito.
La organización de un repositorio en Hugging Face
Cada modelo en Hugging Face se estructura en tres secciones principales:
- Tarjeta del modelo (Model Card): Contiene la descripción del modelo, detalles arquitectónicos, pruebas de rendimiento, licencia y otros aspectos relevantes.
- Sección de archivos (Files): Aquí se encuentran todos los archivos necesarios para cargar y ejecutar el modelo.
- Sección de comunidad (Community): Un espacio colaborativo donde los usuarios pueden compartir experiencias, mejoras y preguntas sobre el modelo.
En este artículo nos enfocaremos en la sección de archivos, explicando la función de cada uno de ellos.
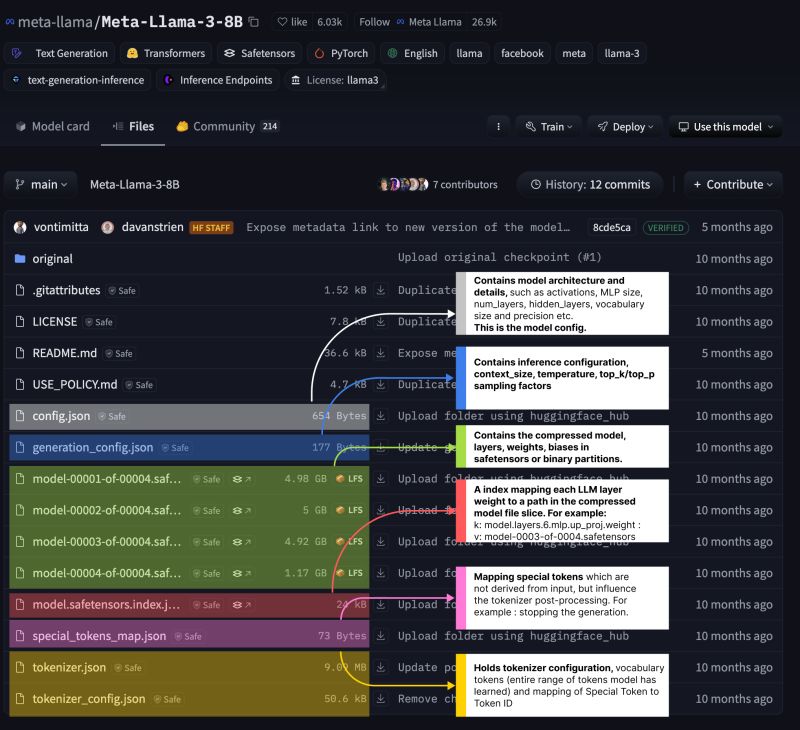
Los archivos clave en un modelo de Hugging Face
a) Configuración de la arquitectura – config.json
Este archivo contiene los metadatos sobre la arquitectura del modelo, como:
- Tamaño de las capas
- Número de cabezales de atención
- Tamaño del vocabulario
- Precisión de los pesos
El archivo config.json es fundamental porque permite que la librería transformers de Hugging Face pueda reconstruir la arquitectura del modelo sin necesidad de especificar manualmente estos parámetros.
b) Pesos del modelo – model-00001-of-00004.safetensors (y otros similares)
Los modelos de lenguaje contienen miles de millones de parámetros, lo que los hace extremadamente pesados. Para facilitar su descarga y almacenamiento, los pesos del modelo se dividen en múltiples archivos, por ejemplo:
model-00001-of-00004.safetensors
model-00002-of-00004.safetensors
model-00003-of-00004.safetensors
model-00004-of-00004.safetensorsEstos archivos contienen los pesos de las capas del modelo en formato binario. El formato safetensors es una alternativa más segura al formato pickle de PyTorch, ya que previene la ejecución de código malicioso durante la carga del modelo.
c) Mapeo de capas – model.safetensors.index.json
Dado que los modelos suelen dividirse en múltiples archivos de pesos, este archivo actúa como un índice que mapea qué parte del modelo está en cada uno de estos archivos. Por ejemplo:
{
"metadata": {},
"weight_map": {
"layer1.weight": "model-00001-of-00004.safetensors",
"layer2.weight": "model-00002-of-00004.safetensors"
}
}Este mapeo permite que Hugging Face cargue el modelo correctamente sin importar en cuántos archivos se dividan los pesos.
d) Configuración del tokenizador – tokenizer.json y tokenizer_config.json
Estos archivos definen cómo se procesan los textos antes de ingresar al modelo.
tokenizer.json: Contiene el vocabulario completo del modelo y la información de los tokens.tokenizer_config.json: Define parámetros específicos del tokenizador, como el modelo de tokenización utilizado y reglas especiales de segmentación de palabras.
El tokenizador convierte el texto en una secuencia de tokens que el modelo puede entender y procesar.
e) Tokens especiales – special_tokens_map.json
Algunos modelos utilizan tokens especiales para tareas específicas. Este archivo asigna tokens a funciones especiales como:
[CLS]– Token de clasificación[SEP]– Token separador de texto[MASK]– Token para enmascaramiento en modelos de entrenamiento
Estos tokens permiten que el modelo maneje estructuras específicas en distintas tareas de procesamiento de lenguaje natural.
f) Configuración de Generación – generation_config.json
Este archivo almacena los parámetros que controlan cómo el modelo genera texto en la inferencia. Algunos de los parámetros más importantes son:
- Temperatura: Controla la aleatoriedad en la generación de texto.
- Top-k y Top-p Sampling: Métodos para seleccionar las palabras más probables en la generación.
- Ventana de contexto: Cantidad de tokens que el modelo puede procesar en una sola predicción.
Esta configuración permite ajustar la creatividad y precisión del modelo al generar texto.
Comprender la estructura de archivos en un modelo de Hugging Face es crucial para su implementación eficiente. Desde la configuración de arquitectura hasta los pesos del modelo, cada archivo cumple una función específica que permite la correcta ejecución del modelo. Con esta introducción, ahora tienes una visión clara de cómo están organizados estos archivos y cómo influyen en el rendimiento del modelo. Hay mucho más pero al menos esto cubre lo básico para interpretar cada uno de estos archivos. 🚀

