Hoy vamos a repasar uno de los puntos fundamentales de una estrategia SEO, el análisis de los logs del servidor. Qué información se encuentra aquí, cómo analizarla y ya que estamos cómo explorarla haciendo uso de un sencillo framework en Python desarrollado por Elias Dabbas a través de su librería advertools.
Qué podemos encontrar en un log del servidor
Desglosamos una línea de ejemplo de ghendigital.com:
34.238.192.0 - - [11/Jun/2024:08:09:44 -0400] "GET /robots.txt HTTP/1.1" 200 119 "-" "CCBot/2.0 (https://commoncrawl.org/faq/)"
Cada línea del archivo de log representa una solicitud HTTP y contiene la siguiente información:
- Dirección IP del cliente: Identifica la dirección IP desde la cual se realizó la solicitud.
- Identificación del cliente (RFC 1413): Generalmente un guion
-, ya que rara vez se utiliza. - Usuario autenticado: Generalmente un guion
-, a menos que haya autenticación. - Fecha y hora de la solicitud: La fecha y hora exactas en las que se realizó la solicitud.
- Solicitud HTTP: Incluye el método HTTP (GET, POST, etc.), la ruta solicitada y la versión del protocolo HTTP.
- Código de estado HTTP: El código de estado de la respuesta HTTP (200, 404, 500, etc.).
- Tamaño del objeto: El tamaño del objeto devuelto al cliente.
- Referencia: La URL de la página desde la que se realizó la solicitud (si existe).
- Agente de usuario: Información sobre el navegador o cliente que realizó la solicitud.
Para analizar este archivo de logs y obtener información valiosa para mejorar tu estrategia SEO, podemos enfocarnos en varios aspectos:
- Identificar Errores 404: Detectar las páginas solicitadas que no existen para corregir enlaces rotos o crear redirecciones.
- Análisis de Bots: Verificar qué bots están rastreando tu sitio y con qué frecuencia.
- Tráfico de Usuarios: Identificar las páginas más visitadas y las fuentes de referencia.
- Rendimiento del Servidor: Revisar códigos de estado HTTP para detectar problemas en el servidor.
- Tamaño de Respuestas: Verificar el tamaño de las respuestas para identificar posibles problemas de rendimiento.
Nada mejor que verlo en un caso de uso específico. ¡Vamos allá!
Preparando los datos
Una vez hemos descargado el archivo que contiene los logs desde nuestro servidor vamos a cargarlo y utlizar el framework de advertool. Aqui les dejo la documentación y el repo de Gituhub.
Lo primero es instalar las dependencias para este proyecto
import advertools as adv
import pandas as pd
from ua_parser import user_agent_parser
import matplotlib.pyplot as plt
import seaborn as snsEn el framework hay parsers que vienen por defecto, pero, dada la variedad de formatos en los regitros de logs puede que no sea posible estandarizarlo. Es lo que me pasó a mi y por ello tuve que definir reglas personalizadas.
# Cargar el archivo de logs para ver su contenido
file_path = 'nginx_logs'
with open(file_path, 'r') as file:
log_data = file.readlines()
# Mostrar las primeras líneas del archivo para tener una idea de su estructura
log_data[:10]
# Definimos la expresión regular personalizada y los campos
log_pattern = (
r'^(?P<server>[^ ]+) (?P<service>[^ ]+) "(?P<country>[^"]*)" (?P<ip>[^ ]+) - - '
r'\[(?P<datetime>[^\]]+)\] "(?P<method>[^ ]+) (?P<url>[^ ]+) (?P<protocol>[^"]+)" '
r'(?P<status>\d+) (?P<size>\d+) "(?P<referer>[^"]*)" "(?P<user_agent>[^"]+)" "(?P<client_ip>[^"]+)"$'
)
fields = [
"server", "service", "country", "ip", "datetime", "method", "url", "protocol",
"status", "size", "referer", "user_agent", "client_ip"
]
# Usamos la función logs_to_df de advertools
adv.logs_to_df(
log_file="nginx_logs",
output_file="adv_logs.parquet",
errors_file="log_errors.csv",
log_format=log_pattern,
fields=fields,
)
Luego del parseo verificamos que el dataframe que se ha creado contenga datos y adicionalmente revisamos el archivo generado por advertool de errores que contiene aquellas lineas que por su variedad, sintaxis, etc. no se pudieron incluir en el Dataframe. Una ventaja de trabajar con un archivo .parquet es que se trata de un formato abstracto que nos permite maximizar el rendimiento del recorrido para cuando tenemos miles/millones de urls.
# Verifica si el archivo Parquet contiene datos
logs_df = pd.read_parquet('adv_logs.parquet')
print(f"Número de filas en el DataFrame: {logs_df.shape[0]}")
if logs_df.empty:
print("El DataFrame está vacío. Revisa los errores en adv_errors.txt.")
# Revisa si el archivo de errores tiene contenido
with open('adv_errors.txt', 'r') as f:
errors = f.read()
if errors:
print("Errores encontrados durante el parseo:")
print(errors)
# Asegúrate de que las columnas esperadas están presentes
print("Columnas del DataFrame:")
print(logs_df.columns)
Convertimos el tipo de dato de fecha «datetime» en un tipo de datos datetime para poder tratarlo como una fecha y no como una cadena de texto
logs_df = pd.read_parquet('adv_logs.parquet')
# Convertir 'datetime' a tipo datetime
logs_df['datetime'] = pd.to_datetime(logs_df['datetime'],
format='%d/%b/%Y:%H:%M:%S %z')Realizamos un reverse DNS sobre la columna de direcciones IP para facilitarnos la tarea de encontrar el nombre del dominio asociado a estas direcciones. Esto es útil para:
- Verificación: Ayudar a confirmar la identidad del remitente en correos electrónicos y otros servicios.
- Diagnóstico de Red: Facilitar el diagnóstico y solución de problemas de red.
- Seguridad: Identificar posibles ataques y gestionar listas blancas o negras.
# Realizar el reverse DNS lookup
host_df = adv.reverse_dns_lookup(logs_df['ip'])
ip_host_dict = dict(zip(host_df['ip_address'], host_df['hostname']))
logs_df['hostname'] = [ip_host_dict.get(ip, 'unknown') for ip in logs_df['ip']]
#Agregamos una columna al Data Frame para los hostnames
ip_host_dict = dict(zip(host_df['ip_address'], host_df['hostname']))
logs_df['hostname'] = [ip_host_dict[ip] for ip in logs_df['ip']]Luego podemos hacer cosas interesantes con el framework de Elias como por ejemplo profundizar en la estructura de urls
request_url_df = adv.url_to_df(logs_df['url'])
request_url_df = request_url_df.add_prefix('url_')
request_url_df.head(10)Otro uso interesante de advertools es profundizar sobre los user agents e icorporarlos a un data frame final
ua_df = pd.json_normalize([user_agent_parser.Parse(ua) for ua in logs_df['user_agent']])
ua_df.columns = 'ua_' + ua_df.columns.str.replace('user_agent\.', '', regex=True)
ua_df.head(10)Concatenamos los DF en un archivo final y tendremos listo nuestro documento para analizar
(pd.concat([logs_df, request_url_df, referer_url_df, ua_df], axis=1)
.to_parquet('adv_logs_final.parquet', index=False, version='2.4'))Análisis de Log
Comenzamos con la magia! Ahora todo se trata de definir preguntas que nos permitan conocer/obtener información de nuestro Data Frame. Aquí vamos con algunos ejemplos:
1. ¿Cuáles son los TOP Bots que rastrean mi sitio?
top_bots = pd.read_parquet('adv_logs_final.parquet',
filters=[
('ua_device.family', '==', 'Spider')
],
columns=['ua_device.family', 'ua_family'])['ua_family'].value_counts()
top_bots[:15]Respuesta
Googlebot 11143
AdsBot-Google 3135
bingbot 2376
MJ12bot 1160
SemrushBot 998
WhatsApp 755
WordPress 597
Taboolabot 561
YandexBot 535
AhrefsBot 451Observaciones:
- Googlebot es, con diferencia, el bot más activo en el sitio.
- Otros bots como AdsBot-Google y bingbot también tienen una presencia significativa.
Propuestas:
- Focalizar la Optimización: Dado que Googlebot realiza la mayoría de las solicitudes, se debe priorizar la optimización para Google.
Monitoreo de Otros Bots: Revisar el impacto de otros bots y asegurarse de que no consuman excesivamente los recursos del servidor.
2. ¿Cuál es el tráfico por horas en mi servidor?
# Análisis de tráfico por hora
final_df['hour'] = final_df['datetime'].dt.hour
traffic_by_hour = final_df['hour'].value_counts().sort_index()
print(traffic_by_hour)Respuesta:
hour
0 6205
1 6281
2 8021
3 15594
4 17083
5 15989
6 20017
7 30561
8 39640
9 42113
10 5662
21 1892
22 11562
23 7610Resultados:
- El tráfico es significativamente mayor entre las 3 AM y las 10 AM, alcanzando su pico a las 9 AM con 42,113 solicitudes.
Observaciones:
- Existe un patrón claro de tráfico con picos específicos a lo largo del día.
Propuestas:
- Ajuste del Crawl Budget: Considerar ajustes en el crawl budget durante las horas de menor tráfico para equilibrar la carga del servidor.
- Análisis de Impacto: Evaluar si los picos de tráfico coinciden con caídas en el rendimiento del sitio.
3. ¿Cuál es la distribución de respuestas arrojadas por el status global del servidor?
# Análisis de códigos de estado HTTP
status_counts = final_df['status'].value_counts()
print(status_counts)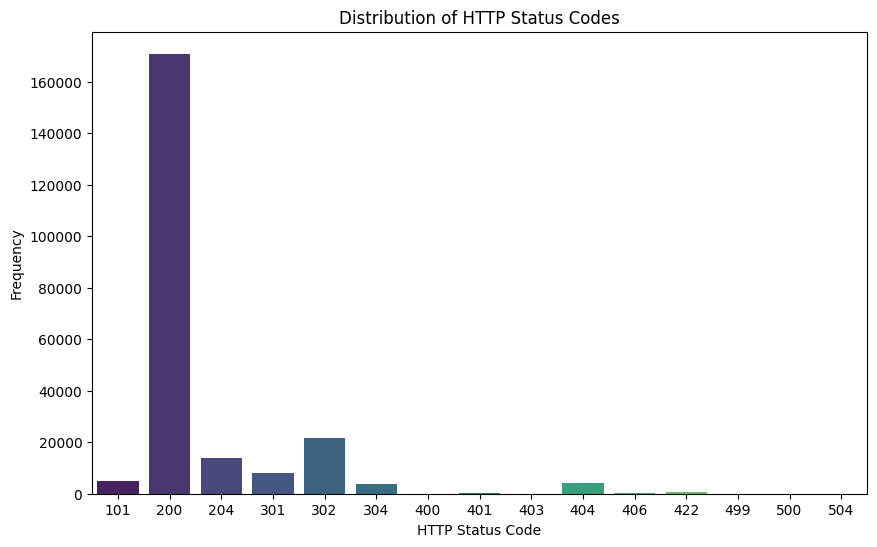
Resultados:
- 200 OK: 170,885 solicitudes
- 302 Found: 21,550 solicitudes
- 204 No Content: 13,863 solicitudes
- Otros códigos incluyen 301, 101, 404, 304, entre otros.
Observaciones:
- La mayoría de las respuestas son exitosas (código 200).
- Hay un número notable de redirecciones (códigos 301 y 302).
Propuestas:
- Revisar Redirecciones: Minimizar redirecciones innecesarias para mejorar la eficiencia del rastreo.
- Mejora de Contenidos: Asegurarse de que las páginas importantes no devuelvan códigos 4xx o 5xx.
4. ¿Googlebot está solicitando principalmente contenido mobile o desktop?
# Identificar solicitudes de Googlebot Mobile y Desktop
googlebot_mobile = googlebot_df[googlebot_df['user_agent'].str.contains('Mobile', na=False)]
googlebot_desktop = googlebot_df[~googlebot_df['user_agent'].str.contains('Mobile', na=False)]
# Contar solicitudes
googlebot_mobile_count = googlebot_mobile.shape[0]
googlebot_desktop_count = googlebot_desktop.shape[0]
print(f"Solicitudes de Googlebot Mobile: {googlebot_mobile_count}")
print(f"Solicitudes de Googlebot Desktop: {googlebot_desktop_count}")
# Graficar las solicitudes
plt.figure(figsize=(8, 6))
sns.barplot(x=['Mobile', 'Desktop'], y=[googlebot_mobile_count, googlebot_desktop_count], palette="magma")
plt.title('Solicitudes de Googlebot: Mobile vs Desktop')
plt.ylabel('Número de Solicitudes')
plt.show()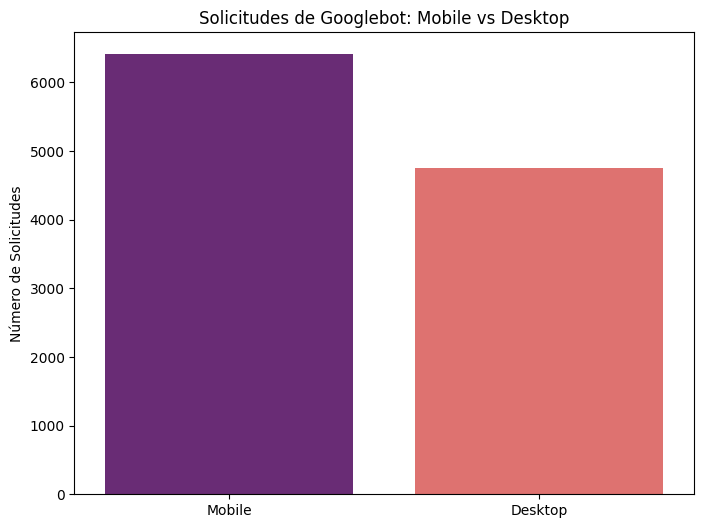
5. Top URLs con Mayor Tamaño de Solicitud
# Filtrar las solicitudes de Googlebot
googlebot_df = final_df[final_df['user_agent'].str.contains('Googlebot')]
# Identificar las top URLs con mayor tamaño de respuesta
top_urls_size = googlebot_df.groupby('url')['size'].sum().sort_values(ascending=False).head(10)
print("Top URLs con mayor tamaño de respuesta:")
print(top_urls_size)
# Graficar las top URLs con mayor tamaño de respuesta
plt.figure(figsize=(10, 6))
sns.barplot(y=top_urls_size.index, x=top_urls_size.values, palette="coolwarm")
plt.title('Top URLs con Mayor Tamaño de Respuesta en Solicitudes de Googlebot')
plt.xlabel('Tamaño de Respuesta (Bytes)')
plt.ylabel('URL')
plt.show()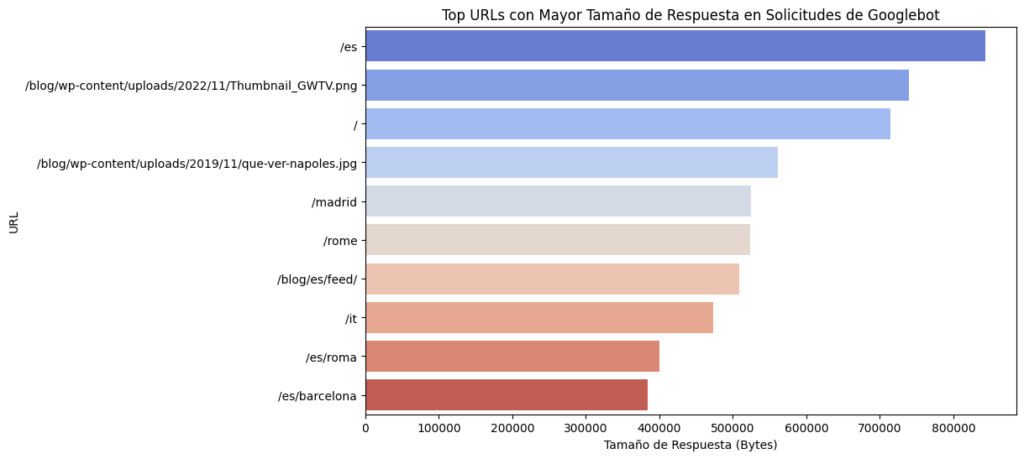
Resultados:
- Páginas y recursos con grandes tamaños de respuesta pueden ralentizar la carga del sitio.
Propuestas:
- Reducción de Tamaños: Optimizar el contenido para reducir los tamaños de respuesta, incluyendo la compresión de imágenes y la minificación de scripts.
- Análisis de Contenidos: Revisar los contenidos de estas páginas para asegurarse de que solo incluyen los elementos necesarios.
6. Tipos de contenidos solicitados dentro de top_url_size
# Extraer el tipo de contenido de las URLs
content_type_df = googlebot_df['url'].str.extract(r'(\.[a-zA-Z0-9]+)$')[0].value_counts().head(10)
print("Tipos de contenido más frecuentes:")
print(content_type_df)
# Graficar los tipos de contenido más frecuentes
plt.figure(figsize=(10, 6))
sns.barplot(y=content_type_df.index, x=content_type_df.values, palette="coolwarm")
plt.title('Tipos de Contenido Más Frecuentes en Solicitudes de Googlebot')
plt.xlabel('Número de Solicitudes')
plt.ylabel('Tipo de Contenido')
plt.show()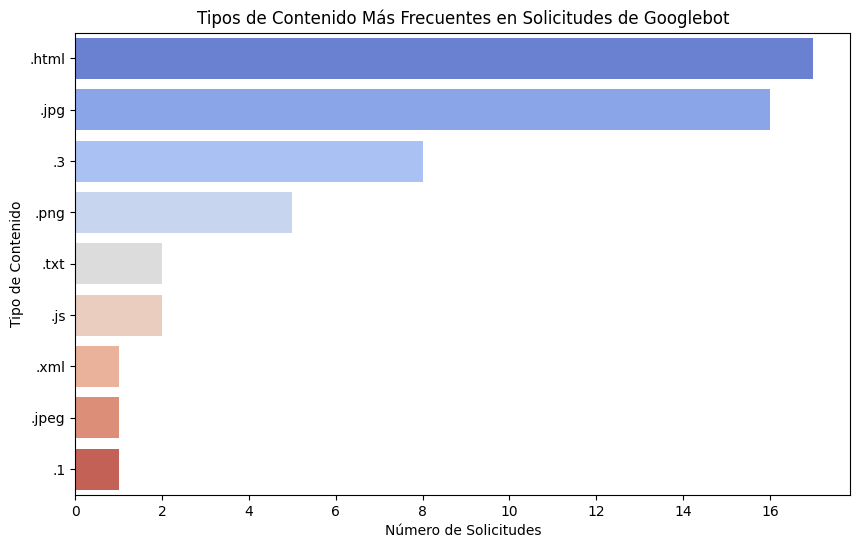
Resultados:
- Los tipos de contenido más frecuentes incluyen .html, .jpg, .png, .txt, .js, entre otros.
Observaciones:
- La variedad de tipos de contenido solicitados sugiere la necesidad de optimizar diferentes tipos de recursos.
Propuestas:
- Optimización de Recursos: Implementar técnicas de optimización para cada tipo de contenido, como la compresión de imágenes y la minificación de archivos JS y CSS.
Conclusiones
El análisis de logs ha revelado varias áreas clave que requieren atención para mejorar la estrategia SEO. Las recomendaciones proporcionadas se enfocan en la optimización de contenidos, la gestión eficiente del crawl budget, la corrección de errores y la mejora del rendimiento del sitio.
Implementación:
- Auditoría y Corrección de Errores: Iniciar con la corrección de enlaces rotos y la optimización de las páginas con errores.
- Optimización de Contenidos: Implementar técnicas de optimización para reducir los tamaños de respuesta y mejorar la velocidad de carga.
- Ajustes de Crawl Budget: Trabajar en conjunto con los equipos técnicos para ajustar la configuración del crawl budget en Google Search Console.
- Monitoreo y Mejora Continua: Establecer un sistema de monitoreo continuo para detectar y corregir problemas rápidamente.
Estas acciones contribuirán significativamente a mejorar el rendimiento del sitio web y la eficiencia del rastreo por parte de Googlebot, impactando positivamente en el SEO general del sitio.
Espero que este ejercicio sirva para conocer mejor este framework de analisis de log para seo y que puedas implementar tus propias preguntas y soluciones. Todo aporte es bienvenido =)

