En este artículo, exploraremos en detalle el proceso de evaluación de un sistema RAG (Retrieval Augmented Generation) desarrollado para el reto Cofares. Este sistema, diseñado para recomendar productos farmacéuticos basados en consultas de usuarios, ha sido sometido a una rigurosa evaluación en diferentes métricas ofrecidas por el sistema de evaluación de Gen AI. Repasemos cómo utilizar este framework para evaluar nuestra app IA.
¿Qué es un Sistema RAG y por qué es importante evaluarlo?
Un sistema RAG combina la potencia de los modelos de lenguaje grandes (LLMs) con la capacidad de recuperar información relevante de una base de datos. En nuestro caso, el sistema RAG ha sido entrenado para comprender las consultas de los usuarios sobre productos farmacéuticos y proporcionar respuestas precisas y relevantes basadas en una base de datos de 43.000 productos.
Algunas métricas para evaluar un sistema RAG te permiten revisar que:
- Las respuestas sean precisas: El sistema debe proporcionar información correcta y relevante sobre los productos.
- Las respuestas sean coherentes: Las respuestas deben ser lógicas y coherentes con la consulta del usuario.
- El sistema sea seguro: Las respuestas no deben contener información engañosa o perjudicial.
- El sistema sea útil: Las respuestas deben satisfacer las necesidades del usuario y ayudarlo a encontrar la información que busca.
Metodología de Evaluación RAG
Para evaluar nuestro sistema RAG, hemos utilizado una combinación de métricas objetivas y subjetivas.
Conjunto de Datos de Evaluación
Se ha creado un conjunto de datos de evaluación que incluye:
- Consultas de usuarios: Simulan las preguntas que un usuario real podría hacer.
- Contexto Bigquery: información relevante extraída por bigquery con un algortimo COSINE utilizando Bigquery ML.
- Contexto Reranking: información jerarquizada por el modelo de reranking a partir del contexto de bigquery.
- Respuestas generadas por el modelo: Las respuestas generadas por Gemini flash 1.5 para cada consulta.
Ahora, comencemos con este ejemplo para que entendamos el proceso utilizado en este caso. Voy a simplificar la cantidad de datos de entrenamiento por razones obvias de espacio aquí. Pero según la recomendaciones propias de la base de datos de Google el minimo aconsejable de datos para una muestra «realista» no debería ser menor a 100 ejemplos.
# ----------------------Dataset----------------------
"""To evaluate the RAG generated answers,
the evaluation dataset is required to contain the following fields:
Prompt: The user supplied prompt consisting of the User Question and the RAG Retrieved Context
Response: The RAG Generated Answer
Your dataset must include a minimum of one evaluation example.
We recommend around 100 examples to ensure high-quality aggregated metrics
and statistically significant results."""
#El siguiente template a sido generado con Gemini a modo de ejemplo de implementación
import pandas as pd
# Ejemplos de preguntas de los usuarios
questions = [
"""Busco una crema para las estrías""",
]
# Contexto recuperado por el sistema RAG (simulación de descripciones de productos relevantes)
retrieved_contexts_by_bigquery = [
"""Nombre: Duplo Farline Crema De Manos Anti_Age, 2 x 50 ml, Descripción: Duplo Farline Crema De Manos Anti-Age ayuda a aclarar las manchas en las manos y contribuye a evitar su aparición. Esta es una crema de acción especial antiedad, cuyos componentes ayudan a difuminar las arrugas y manchas cutáneas: alteraciones de la piel que se presentan en las manos como consecuencia de la exposición solar extrema, así como a causa de la sequedad producida por agentes contaminantes. Al ser aplicada diariamente sobre las manos logra nutrir la piel en profundidad, creando una barrera contra elementos dañinos y rayos solares. Además, es una crema de fácila absorción.Usada regularmente, esta crema de manos ayuda a suavizar la piel y la protege de agentes externos como las radiaciones solares UV, los jabones abrasivos, la sequedad producida por el polvo, el aire frío en invierno y los cambios de temperatura. Entre otros ingredientes contiene aceite de oliva y pantenol, que ejercen una acción suavizante en las manos. El producto está indicado para un público de mediana edad en adelante, o que por cualquier motivo presente una piel envejecida o problemática en las manos. Se presenta en un formato duplo, que incluye dos tubos de esta crema antiedad Farline de 50ml cada uno., Modo de implementación: Te recomendamos aplicar la crema sobre las manos y masajear suavemente hasta su completa absorción.IndicacionesIndicada especialmente para las manos resecas, con manchas o en casos de exposición frecuente a agentes abrasivos.ContraindicacionesConservar en un lugar fresco y seco.No ingerir.Mantener alejado del alcance de los niños., Distancia: 0.35373178452692056 \
generated_answers_by_rerank = [
"""Nombre: CREMA ACEITE ROSA MOSQU 50ML, Descripción: "CREMA DE ACEITE ROSA MOSQUETA. Presentado en un envase de 50 ml. Nutre, regenera, repara y protege la piel, dando una sensación inmediata de suavidad. Contribuye a reducir las arrugas. Mejora el estado de las cicatrices. Aporta a la piel la hidratación y emoliencia necesarias para evitar la sequedad cutánea. Protege de agresiones externas como las variaciones de humedad y temperatura ambientales. Favorece la rápida recuperación del equilibrio fisiológico de la piel. Sin parabenos, no testado en animales. Precauciones: Evitar contacto con los ojos y mucosas.", Modo de implementación: Aplicar dos veces al día, mañana y noche, después de limpiar y tonificar la piel. Repartir la crema por la cara, cuello y escote dando un suave masaje con las yemas de los dedos hasta su completa absorción., Distancia: 0.3748334345316666
]
generated_answers_by_gemini = [
"""{'type': 'product_search', 'message': '¡Hola! He encontrado algunas cremas que podrían ser útiles para las estrías:\n\n* **CREMA ACEITE ROSA MOSQU 50ML:** Esta crema contiene aceite de rosa mosqueta, conocido por sus propiedades regenerativas y cicatrizantes. Puede ayudar a mejorar la apariencia de las estrías, haciéndolas menos visibles. Se recomienda aplicar la crema dos veces al día, masajeando suavemente sobre la zona afectada.\n*}]}"""
]
# Creación del DataFrame para el dataset de evaluación
eval_bigquery = pd.DataFrame(
{
"prompt": [
"Answer the question: " + question + " Context: " + item
for question, item in zip(questions, retrieved_contexts_by_bigquery)
],
"response": retrieved_contexts_by_bigquery,
}
)
eval_rerank = pd.DataFrame(
{
"prompt": [
"Answer the question: " + question + " Context: " + item
for question, item in zip(questions, retrieved_contexts_by_bigquery)
],
"response": generated_answers_by_rerank,
}
)
eval_gemini = pd.DataFrame(
{
"prompt": [
"Answer the question: " + question + " Context: " + item
for question, item in zip(questions, retrieved_contexts_by_bigquery)
],
"response": generated_answers_by_gemini,
}
)Con este dataset de ejemplo podremos obtener un df para cada una de las instancias que conforman nuestra app.
Métricas de Evaluación
Se han utilizado una variedad de métricas por defecto en el servicio de Gei AI de Google para evaluar diferentes aspectos del rendimiento del sistema. Puedes revisar los que cada una hace de la siguiente manera:
# ----------------------Metricas----------------------
"""Select and create metrics
You can run evaluation for just one metric, or a combination of metrics.
For this example, we select a few RAG-related predefined metrics."""
# Explore predefined metrics: https://cloud.google.com/vertex-ai/generative-ai/docs/models/metrics-templates
# See all the available metric examples
MetricPromptTemplateExamples.list_example_metric_names()
['coherence',
'fluency',
'safety',
'groundedness',
'instruction_following',
'verbosity',
'text_quality',
'summarization_quality',
'question_answering_quality',
'multi_turn_chat_quality',
'multi_turn_safety',
'pairwise_coherence',
'pairwise_fluency',
'pairwise_safety',
'pairwise_groundedness',
'pairwise_instruction_following',
'pairwise_verbosity',
'pairwise_text_quality',
'pairwise_summarization_quality',
'pairwise_question_answering_quality',
'pairwise_multi_turn_chat_quality',
'pairwise_multi_turn_safety']Resulta interesante también acceder a los prompt que el modelo está utilizando para evaluar una determinada metrica. Por ejemplo esta:
# See the prompt example for one of the pointwise metrics
print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
RESULT:
# Instruction
You are an expert evaluator. Your task is to evaluate the quality of the responses generated by AI models.
We will provide you with the user input and an AI-generated response.
You should first read the user input carefully for analyzing the task, and then evaluate the quality of the responses based on the Criteria provided in the Evaluation section below.
You will assign the response a rating following the Rating Rubric and Evaluation Steps. Give step-by-step explanations for your rating, and only choose ratings from the Rating Rubric.
# Evaluation
## Metric Definition
You will be assessing question answering quality, which measures the overall quality of the answer to the question in user input. The instruction for performing a question-answering task is provided in the user prompt.
## Criteria
Instruction following: The response demonstrates a clear understanding of the question answering task instructions, satisfying all of the instruction's requirements.
Groundedness: The response contains information included only in the context if the context is present in user prompt. The response does not reference any outside information.
Completeness: The response completely answers the question with sufficient detail.
Fluent: The response is well-organized and easy to read.
## Rating Rubric
5: (Very good). The answer follows instructions, is grounded, complete, and fluent.
4: (Good). The answer follows instructions, is grounded, complete, but is not very fluent.
3: (Ok). The answer mostly follows instructions, is grounded, answers the question partially and is not very fluent.
2: (Bad). The answer does not follow the instructions very well, is incomplete or not fully grounded.
1: (Very bad). The answer does not follow the instructions, is wrong and not grounded.
## Evaluation Steps
STEP 1: Assess the response in aspects of instruction following, groundedness, completeness and fluency according to the criteria.
STEP 2: Score based on the rubric.
# User Inputs and AI-generated Response
## User Inputs
### Prompt
{prompt}
## AI-generated Response
{response}Metricas de rendimiento puntual y comparativa
En este caso de uso hemos utilizado dos tipos de métricas:
- Métricas Pointwise: evalúan cada respuesta individualmente sin compararla con otras. Por ejemplo, cada respuesta se puntúa en función de su relevancia o corrección, a menudo utilizando métricas como la exactitud, la precisión o el recuerdo. Este enfoque es útil para evaluar la calidad de cada respuesta por separado.
- Métricas Pairwise: comparan las respuestas de dos en dos para determinar cuál es mejor. Este método suele implicar evaluaciones de clasificación o preferencia, en las que se evalúa la capacidad de un modelo para elegir la respuesta más relevante entre dos opciones. Las métricas por pares son útiles en tareas de clasificación o a la hora de optimizar las preferencias de los modelos.
He utilizado este tipo de métricas porque además de analizar la presición puntual de las respuestas, quería comparar las que fueron generadas por Bigquery en comparación con el reranker. De este modo quedaron definidas:
#Run evaluation with your dataset
rag_eval_bigquery = EvalTask(
dataset=eval_bigquery,
metrics=[
"coherence",
"groundedness",
"safety",
"question_answering_quality",
],
experiment=EXPERIMENT,
)
rag_eval_rerank = EvalTask(
dataset=eval_rerank,
metrics=[
"coherence",
"fluency",
"groundedness",
"safety",
"question_answering_quality",
"pairwise_coherence",
"pairwise_fluency",
"pairwise_safety",
"pairwise_question_answering_quality"
],
experiment=EXPERIMENT,
)
rag_eval_gemini = EvalTask(
dataset=eval_gemini,
metrics=[
"coherence",
"fluency",
"groundedness",
"safety",
"question_answering_quality",
"pairwise_coherence",
"pairwise_fluency",
"pairwise_safety",
"pairwise_question_answering_quality"
],
experiment=EXPERIMENT,
)
result_rag_bigquery = rag_eval_bigquery.evaluate()
result_rag_rerank = rag_eval_rerank.evaluate()
result_rag_gemini = rag_eval_gemini.evaluate()Como resultado se obtiene un experimento que se registra en Google Cloud dentro de VertexAI y en la consola un nuevo dataframe para cada uno de los procesos definidos que podemos visualizar:
#------------- Display evaluation results -------------
"""View summary results
If you want to have an overall view of all the metrics from individual model's evaluation
result in one table, you can use the display_eval_report() helper function."""
display_eval_report(
(
"Model Bigquery Eval Result",
result_rag_bigquery.summary_metrics,
result_rag_bigquery.metrics_table,
)
)Dataframe:
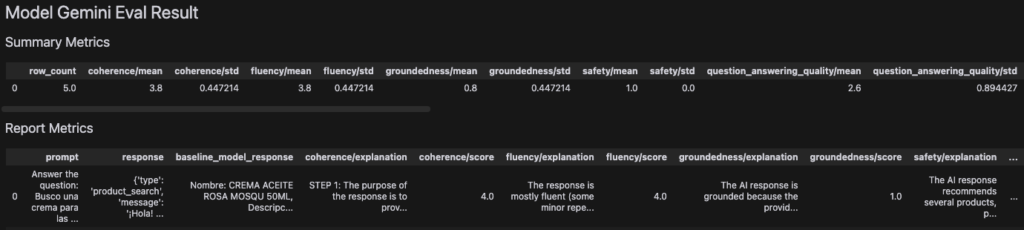
Resultados y Análisis de evaluación GenAI service
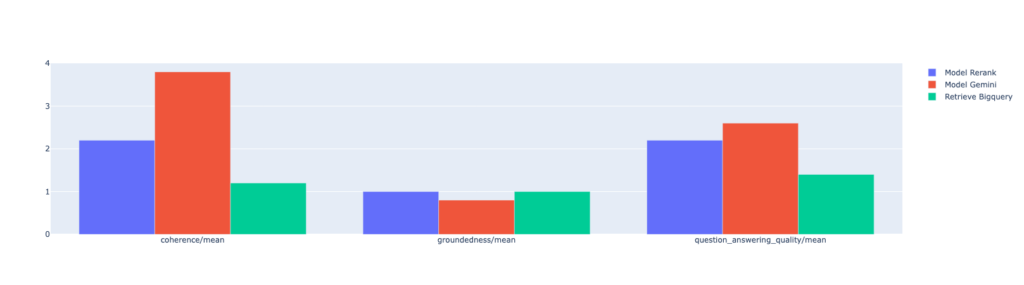
Los resultados de la evaluación muestran que nuestro sistema RAG es capaz de generar respuestas coherentes y relevantes a las consultas de los usuarios sobre productos farmacéuticos. En este caso obtuvimos unas primeras conslusiones:
- Confirmamos que Rerank mejora la calidad de la respuesta en relacion a Bigquery
- Observamos que Gemini mejora la coherencia con la pregunta del usuario, pero se aleja de la realidad provista por la base de datos. En el ejemplo la descripción en la bas de datos no menciona «estrías» dentro de la descripción del producto, sin embargo, Gemini la recomienda específicamente para ese uso.
A través del análisis de las métricas, hemos podido identificar las fortalezas y debilidades del sistema y proponer mejoras futuras.
La evaluación realizada ha demostrado la viabilidad de utilizar un sistema RAG para recomendar productos farmacéuticos. Sin embargo, es importante continuar trabajando en la mejora del sistema, especialmente en términos de precisión y capacidad para manejar consultas más complejas y un dataset más extenso.
Próximos Pasos en este experimento IA
- Ampliar el conjunto de datos de evaluación: Incorporar más ejemplos de consultas y contextos para mejorar la generalización del modelo.
- Explorar nuevas métricas: Investigar otras métricas que puedan ser relevantes para la evaluación de sistemas RAG en el dominio farmacéutico.
- Afinar el prompt del modelo: Experimentar con diferentes prompts para que Gemini no invente cosas que no están en la descripción de los productos.
En conclusión, este trabajo presenta un primer paso hacia la creación de un sistema de recomendación de productos farmacéuticos basado en IA. Los resultados obtenidos son prometedores y abren nuevas posibilidades para mejorar la experiencia del usuario en el sector farmacéutico.